Learning to code as a cross-grade level educational goal seems an educational trend. I attribute this to two factors: a) assumptions about the vocational potential of having coding skills and b) the promotion that coding experiences develop computational thinking which while somewhat ambiguous seems a form of higher-order thinking.
There are many strategies for how to go about learning coding and what type of coding is appropriate for students at different grade levels. We include a chapter on coding in our textbook and I have generated related resources available online. One of the interesting issues I think has received little attention is the transfer value of learning in what might be described as a coding language and environment designed to teach core coding concepts while reducing many of the demands of working in a traditional programming language to the development of proficiency in the traditional language. For example, many of the educational coding environments for younger learners use icons instead of text.
When I began writing about coding in the early 1990s, I mostly focused on the logic and specifics of LOGO. This was a text-based language, but somewhat forgiving when it came to syntax. Such text-based approaches eventually gave way to icon-based systems assumed to allow a focus on coding concepts without the demands of exact syntax.
A grad student in one of my classes was interested in the Python programming language and found that Python could import a subset of commands for LOGO. She was working on tutorials to guide students in the use of this implementation of LOGO. I had loaded Python on my Mac, but had not really done much with the language. I kind of need a project to motivate my exploration. However, I was familiar with LOGO and this was enough to encourage my exploration. What follows is my description of what others might do to explore. I see some opportunity in the natural transition that might occur using a language within a language.
Getting your system set up was my biggest obstacle. I will explain why as I continue.
Get Python from a reliable source
Python will be saved as a folder in your applications list. Python is accessed from the Terminal. The easiest way to activate the Terminal and Python within the terminal is to use the IDLE app that appears in the Python folder [see image]. I just drag IDLE to the toolbar at the bottom of the screen for easy access. IDLE is an Integrated Development Environment (IDE) including a code editor and debugger. The code editor is the tool within which you write Python code.
It is easy to find tutorials for Python on the Internet. The tutorials are great as far as the coding itself was concerned and my background allowed me to make assumptions about how things are accomplished via code. My existing experience with coding in other languages made exploring a new situation fairly easy. Once you are used to defining variables, loops, conditionals, etc., the basics come easily. I have not moved past the basics. What I struggled with were some very basic things I needed to know for saving, loading, and running code. I had to look around for a while to get past writing and running code within the IDLE window. The key came from a YouTube video that allowed me to understand that you simply open a file from within the Terminal and enter your code in this blank file rather than enter code in the Terminal and then save your work as a file. This is evidently so obvious to those creating tutorials that they fail to mention the difference. If you create two files in the ways I have described and examine what is saved in both cases, you immediately see the difference.
There is little value of me developing complete tutorials as others have already done an excellent job. Here are a couple of resources.
Basics of Python
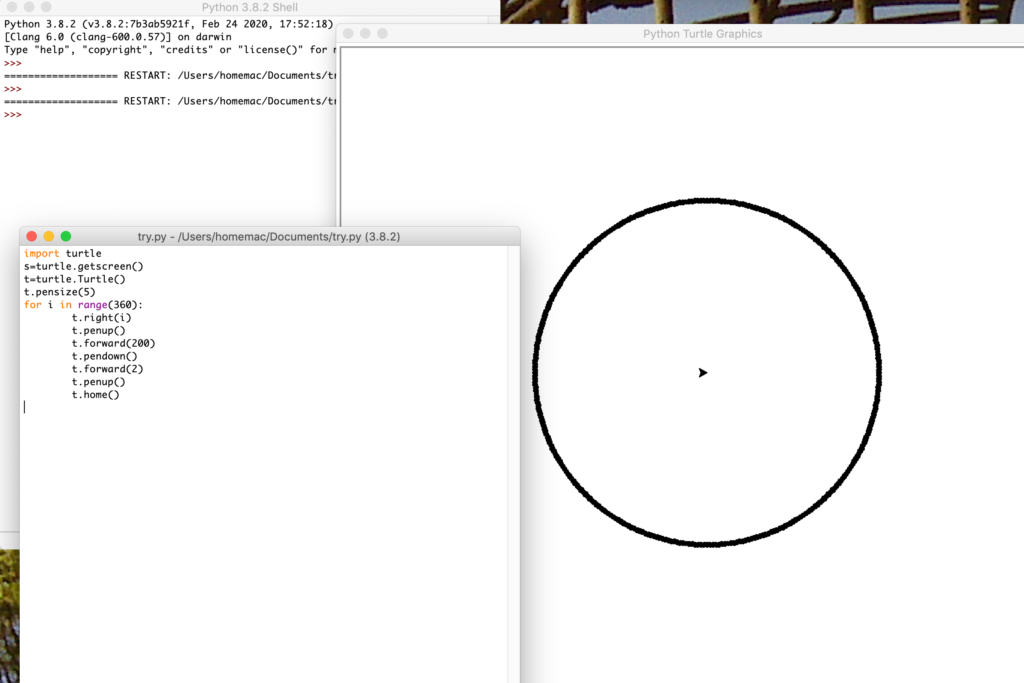
An example I like to use to explain Seymour Papert’s concept of computational understanding of geometry (in contrast to Euclid’s logical or Descartes’ algebraic approach) using the example of understanding “circle”. The important insight here is what it means to understand and how is understanding different from recalling. So, if you have taken geometry you have probably learned the definition of a circle as “a closed plane figure consisting of all points equidistant from a point”. The circle program I write in LOGO demonstrates what this means. It starts from a point, moves forward the number of turtle steps specified, makes a point, and then returns home. It then turns one degree and repeats the process. Do this 360 time and you have computationally drawn a circle.
The following image demonstrates what this would look like. It shows the Terminal window, the commands in a new file window, and the window containing the result of running the program.
This video shows the program being executed.
![]()



You must be logged in to post a comment.