Have you had the experience of coming across an application feature and wondering why did a software designer decide to go to the trouble of creating and then shipping that feature? Somewhere I encountered a comment on an Obsidian feature called an Unlinked Mention. It took me some time to find it and then even more time in an effort to understand why it exists. I am still not certain how it is to be used and why there wouldn’t be similar features that would be more useful. I have come up with one way I find it offers some value so I will explain what seems a hack and then hope others can find my description helpful in encouraging similar or additional uses.
Note: My description and proposed actions are based on Obsidian on a computer. Some of the actions I describe I could not get to work on my iPad.
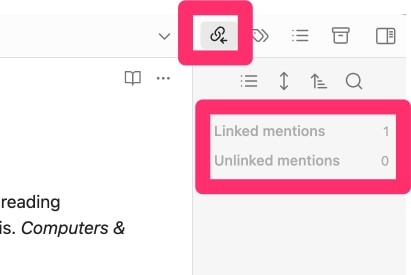
So, I think an unlinked mention is supposed to be understood as something like a backlink. In Obsidian when you create a link among two notes (A – B), Obsidian recognizes but does not automatically display the backlink (B-A). For a given note (A), you can get Obsidian to display any backlinks to that note using the backlinks option for the right-hand panel of the Obsidian display. For the note that is active in the middle panel, the right-hand panel should indicate linked mentions and unlinked mentions. You may have to select which you want displayed and it is possible nothing will be displayed for either option. The linked mentions are the backlinks and you can select and display the backlinked notes from this display.
The unlinked mentions are other notes that contain the same exact phrase as you have used to title Note A. Who knew? Why? Maybe I never quite understood the power of a title or how my notes were supposed to be titled. I have tried to think about this and I still don’t get it.
Here is my hack and I think a way to take advantage of unlinked mentions. Start with a blank note and add a title likely to be used within other content you have stored within other notes. To make the effort, your word or phrase would have to be something you want to investigate. I used the word “metacognition” because this is an important concept in the applied cognitive psychology research I read and attempted to apply to educational uses of technology. I have notes about this concept, but the greatest value I found in this hack was taking advantage of all of the Kindle notes and highlights I had stored in Obsidian via Readwise. In my account, there are more than 200 books worth of notes and highlights and the content for each book is often several pages long. I create notes myself as I read, but there is all of this additional content that may contain things I might find useful. Certainly, several of these books would contain content, especially highlights, focused on metacognition.
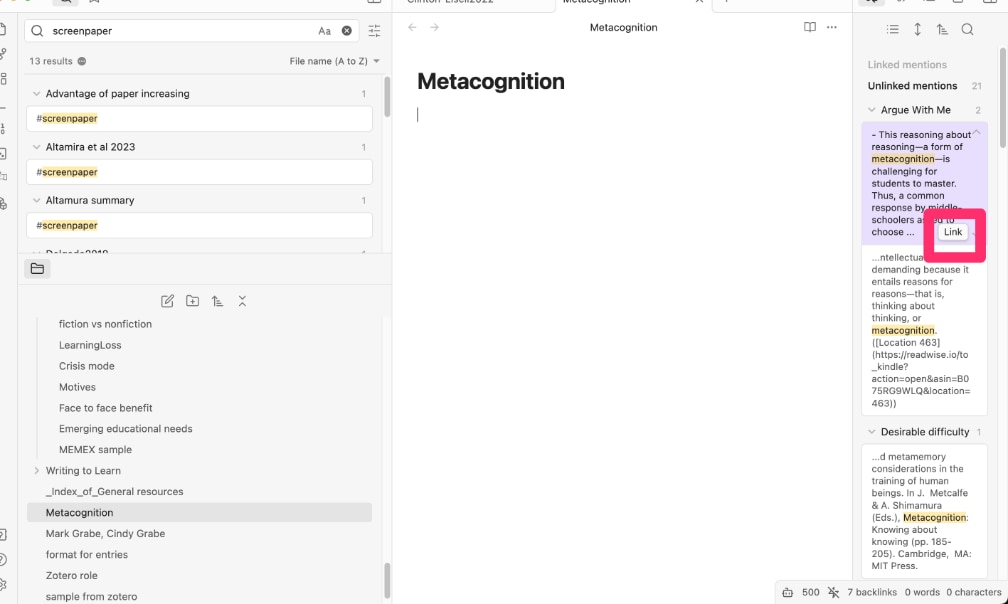
Once I have my new note with the simple title “metacognition” and for this note look under unlinked mentions in the right-hand column, I now have lots of entries. At this point, my note is still blank, but I now can access many other mentions of metacognition from this list of unlinked mentions. If I select one of these mentions, a “link” button appears and if I select this button Obsidian generates a forward link in the A document and adds the A document to my blank B document as a backlink. The B note is still blank.
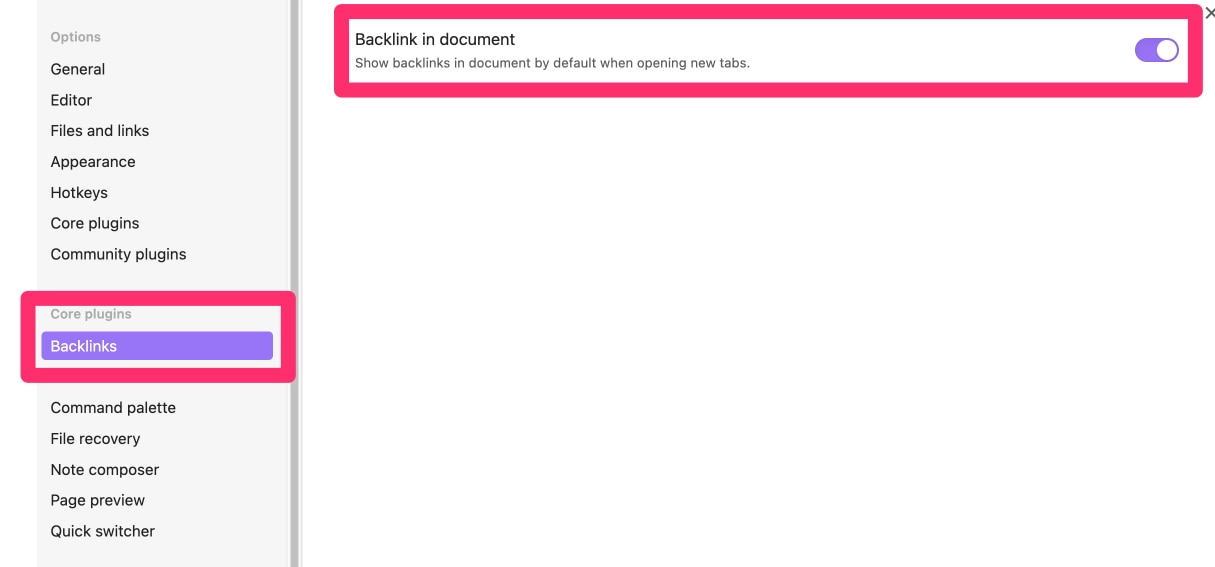
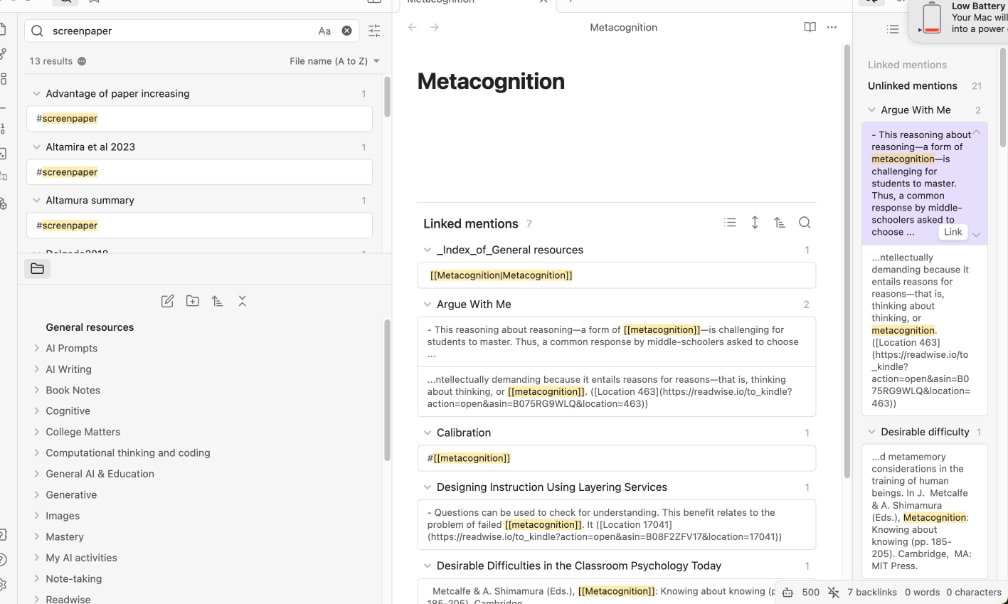
Here comes the hack. One of the core plugins for Obsidians is called backlink (use the gear icon from the panel on the left) and it contains a slider that will display backlinks at the bottom of a note (see following image). Now you can display backlinks on your blank note that allow access to the unlinked content you have linked. See the second image below.
The process I have described is a way to generate a collection of links on a topic that would not be available without this hack. It is the process that finds specific mentions of a concept within much larger bodies of content (the highlights from Kindle books) that I find useful. Give it a try.
Here is a new phrase to add to your repertoire – retrieval generated augmentation (RAG). I think it is the term I should have been using to explain my emphasis in past posts to my emphasis on focusing AI on notes I had written or content I had selected. Aside from my own applications, the role for retrieval generated augmentation I envisioned is as an educational tutor or study buddy.
RAG works in two stages. The system first retrieves information from a designated source and then uses generative AI to take some requested action using this retrieved information. So, as I understand an important difference, you can interact with a large language model based on the massive corpus of content on which that model was trained or you can designate specific content to which the generative capabilities of that model will be applied. I don’t pretend to understand the specifics, but this description seems at least to be descriptive. Among the benefits is a reduction in the frequency of hallucinations. When I propose using AI tools in a tutoring relationship with a student, suggesting to the tool that you want to focus on specific information sources seems a reasonable approximation to some of the benefits a tutor brings.
I have tried to describe what this might look like in previous posts, but it occurred to me that I should just record a video of the experience so those with little experience might see for themselves how this works. I found trying to generate this video an interesting personal experience. It is not like other tutorials you might create in that it is not possible to carefully orchestrate what you present. What the AI tool does cannot be perfectly predicted. However, trying to capture the experience as it actually happens seems more honest.
A little background. The tool I am using in the video is Mem.ai. I have used Mem.ai for some time to collect notes on what I read so I have a large collection of content I can ask the RAG capabilities of this tool to draw on. To provide a reasonable comparison to how a student would study course content, I draw some parallels based on the use of note tags and note titles. Instead of using titles and tags in the way I do, I propose a student would likely take course notes and among the tags label notes for the next exam with something like “Psych1” to indicate a note taken during the portion of a specific course before the first exam to which that note might apply. I hope the parallels I explain make sense.
I recently listened to part of the Senate hearing focused on Big Tech and online child abuse. While recognizing multiple complaints, many legitimate, focused on Big Tech, I am beginning to have a small level of annoyance with the political committees. My reaction to the committee attitude is often – OK, you have identified a problem. You don’t seem to have a solution you want to put forward in legislation beyond complaining about Big Tech and expecting them to come up with a solution. I am not a fan of large technology companies but the situation always seems complicated to me with conflicting values generating complaints and accusations. Since I assume Congress can impose regulations, I want to see the specific solutions they threaten to impose and give everyone a chance to react.
The following is a challenge I sometimes give myself. Here is the problem. I understand some of the issues and ask myself what would I have Congress require. Then, I try to consider what the consequences would be and what complaints would be advanced. I have come up with an ordered list of my recommendations, but first I want to identify some of the common counter-arguments I have considered.
Challenges that are barriers to many potential solutions:
Big is necessary for many services. The most obvious example I can think of would be AI. I know that even major universities cannot independently develop and evaluate the powerful models of big tech companies because of the cost. University researchers do have a more independent view I would like to see in important conversations but doing research and development is difficult. Mandated regulations are easier for big companies to satisfy limiting important competition. Added responsibilities are easier for existing companies with a large user base and solid revenue to address added requirements. Fear of legal action is also more threatening to a company without the cash flow to hire legal counsel and the funds to pay penalties.
I see anonymity as a problem because it allows big tech to be blamed for the behavior of bad actors. Rather than going directly after bad actors demands are made of the platforms the bad actors use. This is the issue addressed by Section 230, but 230 is under attack. Anonymity is defended because it is argued some users need to have their identities protected – children with personal concerns that their parents reject, women hiding from abusive partners, citizens living under oppressive rulers, etc.
Free speech and who gets to interpret what free speech allows is a concern. Given how some politicians use the free speech argument to defend their own behavior trying to regulate harassment and bullying among citizens seems to be problematic. If teens call a peer fat is that free speech?
What would actually change? dana boyd (Microsoft researcher and expert on online adolescent behavior) makes the following argument concerning how politicians see many problems. She contends that most problems have multiple causes with online behavior being one. She argues that the nature of our culture creates an environment such that whatever would be done about Big Tech would result in very little change in the challenges of adolescence.
We as a society become locked into a model we mistakenly understand to be free. We are wrong because we pay for many online services by our assumed attention to ads, but it is the perception of free that is the problem.
Equity – those able to pay for services are less vulnerable in that we can exercise greater control over known threats.
I do not claim that my ordered list of possible actions resolves what I think of as conflicting challenges, but I wanted to recognize these challenges that must be recognized. You may have others you would add to the list.
What I mean by an ordered list is that unless items at the top of the list are addressed, items lower on the list will either be difficult to implement or implementation will be less effective.
I am going to try to present items on my ordered list using a specific structure. In some cases, this is more challenging than in others. I first intend to present a problem, then identify a mechanism that enables the problem (flaw), and finally propose a concrete action that could be taken.
Problem One – lack of competition limiting options that could be based on what users believe to address a personal need. Flaw – the network effect locks individuals into an inferior service because that is where colleagues are. Solution – depending on the service politicians could require that interoperability and easy movement of personal data be provided.
Note: Cory Doctorow makes the argument that many of the nation’s problems will not likely be addressed without better knowledge and communication. I am simply extending his argument to suggest that until online participants have options that address their personal needs and concerns meaningful change will be far less likely. Interoperability and easy movement of data are practical ways to challenge the perception of being locked in.
Problem Two – Collection of personal information. Flaw – the revenue model of big tech is largely based on the collection of personal information to allow targeted ads and communication. Companies pay far more for personalized rather than random access and this higher revenue is what allows for the infrastructure, research and development, high salaries and return to investors necessary to maintain big tech. Solution – the best solution would be to deny or limit the collection of personal information. Making third-party cookies illegal would be helpful, but denying the use of ads and forcing a subscription-based revenue approach would be a better solution. Ad blocking at present is a gray ethical area as it provides no alternative to support work. Moving the financial model to subscriptions would be ideal. Requiring companies to provide ad-supported and ad-free options makes some sense, but presents an equity issue in that more vulnerable people would likely accept what would be an objectionable situation. BTW – my selection of my first priority was related to the equity issue and the importance of meaningful alternatives.
3. Problem – big is necessary for R&D. Flaw – the R&D function of higher education does not allow the budget to contribute to many of the issues now addressed by big tech. Solution – Fund a competitive consortium of higher ed institutions to focus on R&D issues ignored by big tech and evaluate strategies used by big tech for consequences that may be damaging.
4. Problem – holding tech companies accountable for the actions of anonymous bad actors that use tech platforms. Flaw – individuals responsible for actions cannot be identified because of anonymity. Solution – require verification of identity for use. Companies could maintain this information and release it when required by authorities. Issues – increased cost and time, distrust of those who control and access identify data.
5. Problem – online services are addictive increasing dependency even when experiences are negative. Flaw – companies are motivated to increase the amount of use to show more ads. Solution – eliminate easy sources of reward (likes, shares) in favor of more effortful reactions (comments). Note – moving to a subscription model would remove the incentive for showing more ads – see problem 2.
So this is my list. I think what I propose is concrete and that is important in comparison to blaming and failure to define actual options. I invite others to react and to generate concrete actions they think could be implemented.
*****
Like many focused on educational uses of technology, I spend some time exploring AI applications. When sharing AI-generated content, I intend to differentiate what I have written from what I have used AI to create.
I asked ChatGPT to comment on the advantages and disadvantages using moving from ad-supported content and services to a subscription model. I thought the response was worth sharing.
The shift towards subscription models over targeted advertising is a transformative approach that promises a host of benefits, albeit with some trade-offs. Here’s a balanced view on how requiring a subscription instead of relying on targeted ads could shape the future of content consumption, user privacy, and business models.
Pros:
Enhanced Privacy and Security: The most significant advantage of a subscription-based model is the protection of user privacy. Targeted advertising relies on collecting vast amounts of personal data to tailor ads, raising concerns about data misuse and privacy breaches. A subscription model eliminates the need for data harvesting for advertising purposes, thereby enhancing user privacy and reducing the risk of data breaches.
Improved User Experience: Subscriptions can lead to a cleaner, more enjoyable user experience, free from the clutter and intrusion of targeted ads. This can increase user satisfaction and engagement, as content is no longer interrupted by irrelevant or annoying advertisements.
Predictable Revenue Streams: For content creators and platforms, subscriptions provide a stable, predictable source of revenue. This can be especially beneficial for smaller creators or niche platforms, which might struggle to attract advertising dollars but have a dedicated user base willing to pay for quality content.
Encourages Quality Content: A subscription model incentivizes the creation of high-quality, valuable content. Since revenue is directly tied to user satisfaction and willingness to pay, there is a stronger focus on producing content that meets or exceeds user expectations.
Cons:
Barrier to Entry: A subscription fee can act as a barrier to entry, potentially alienating users who are unwilling or unable to pay. This could limit the audience size, particularly in markets where consumers are accustomed to free content supported by ads.
Subscription Fatigue: As more platforms adopt subscription models, users may experience subscription fatigue, feeling overwhelmed by the number of subscriptions they need to manage and pay for. This could lead to a churn rate increase as users prioritize their subscriptions based on value and budget constraints.
Reduced Reach for Advertisers: For advertisers, subscription models mean reduced access to potential customers. Targeted advertising allows brands to reach specific demographics with precision, but a subscription model limits this reach, potentially impacting sales and marketing strategies.
Financial Risk for Creators: Switching to a subscription model presents financial risks, especially if the existing audience is not willing to convert from free to paid content. This could lead to a temporary or permanent dip in revenue during the transition period.
In conclusion, while the shift towards subscription models offers promising solutions to many concerns associated with targeted advertising, it is not without its challenges. Balancing user privacy, content quality, and financial sustainability will be key to successfully implementing this model.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
You must be logged in to post a comment.