Apple appears to be closing the gap with Google when it comes to visual identification (Google Lens). I was taking a walk today and came across an interesting structure as a tree budded out. I was curious what Apple could do with the image I captured.
Apple Photos (iOS) has added the capacity of image identification for certain types of objects. MacRumors says landmarks, plants, and pets, but give it a try for other objects as the capability expands.
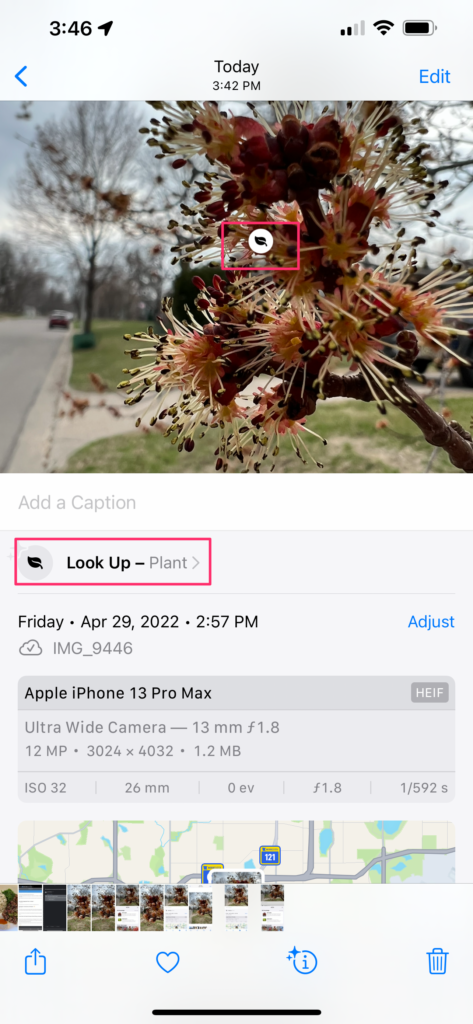
I will take you through the process. Here is the image I captured. Below the image note the Info icon. It has stars around it meaning the system thinks it may be able to identify the image.
If you select the Info icon, the system adds a small leaf to the photo and asks if you want to look up what it knows to be a plant (see red boxes).
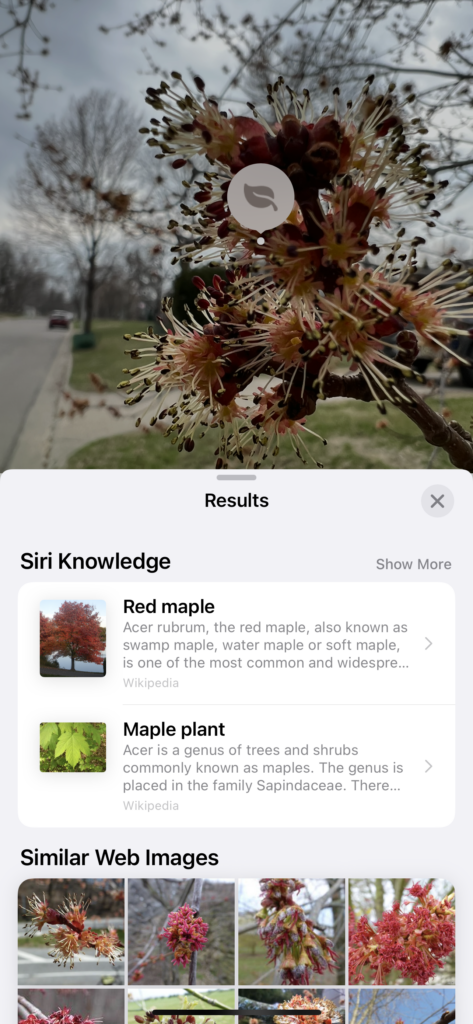
Lookup offers several comparison images and links to sites the system assumes verify the identification. In this case, the “guess” is a red maple. The similarity to the comparison image leads me to accept this as correct.
Google lens still seems more advanced. The following video offers some of my explorations with Google lens.
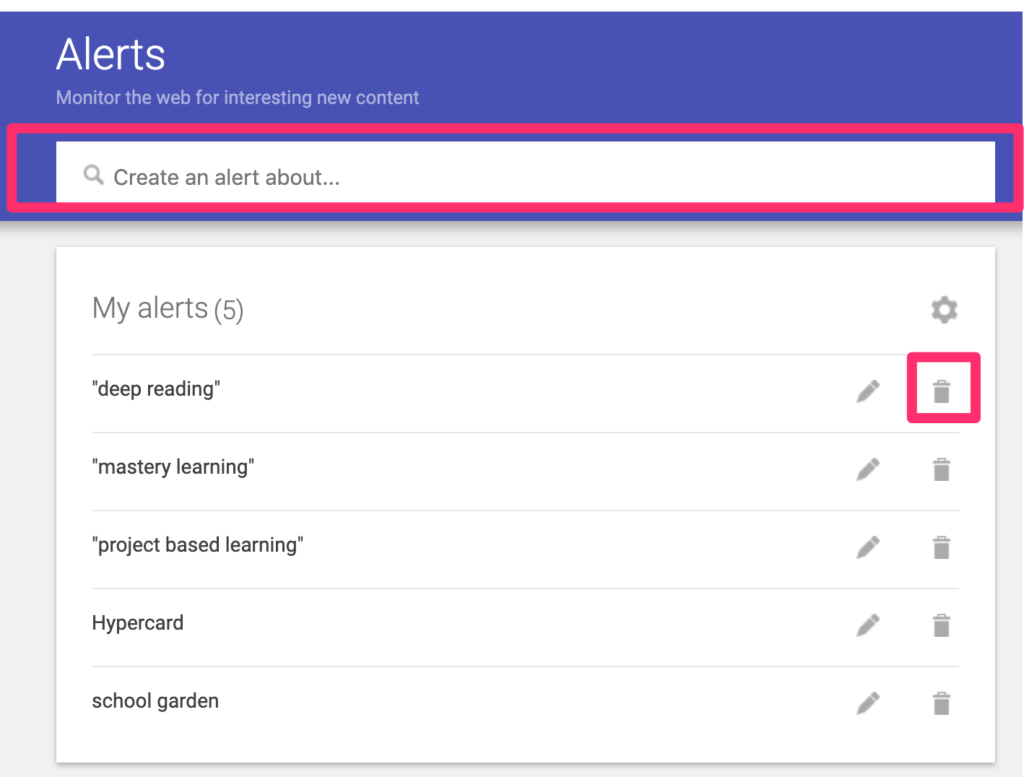
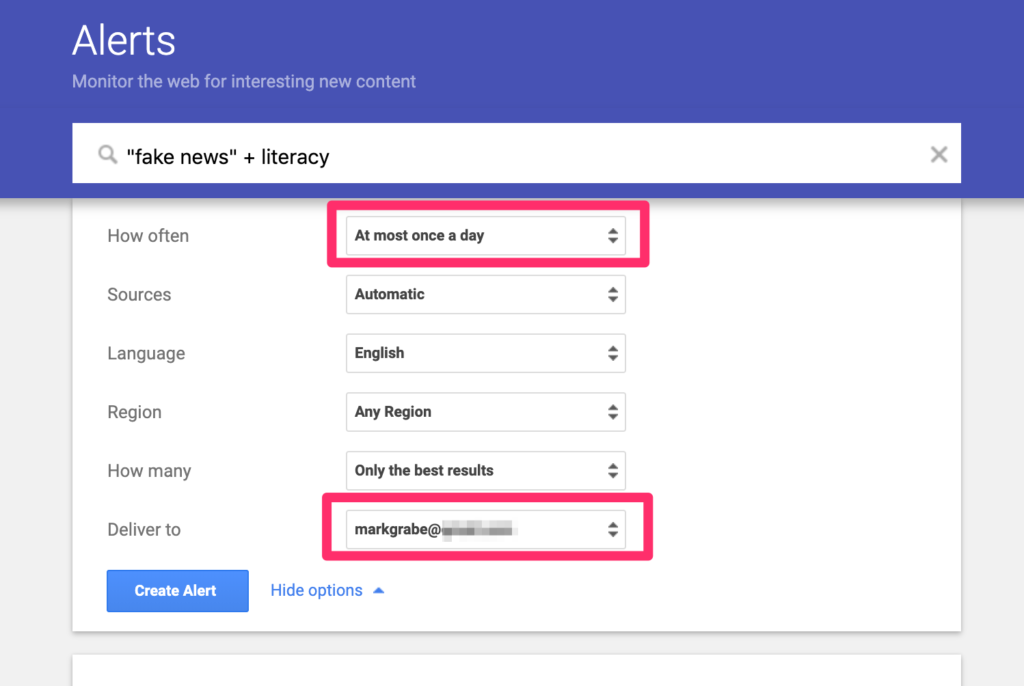
Google Alerts allow a user to create an automatically repeated search that returns results to a designated email address. The easiest way to set up a search is to use the address https://google.com/alerts from your browser. This address will display existing alerts you have established, provide a way to terminate an existing search (see trash can following an existing search), and the search box for a new alert.
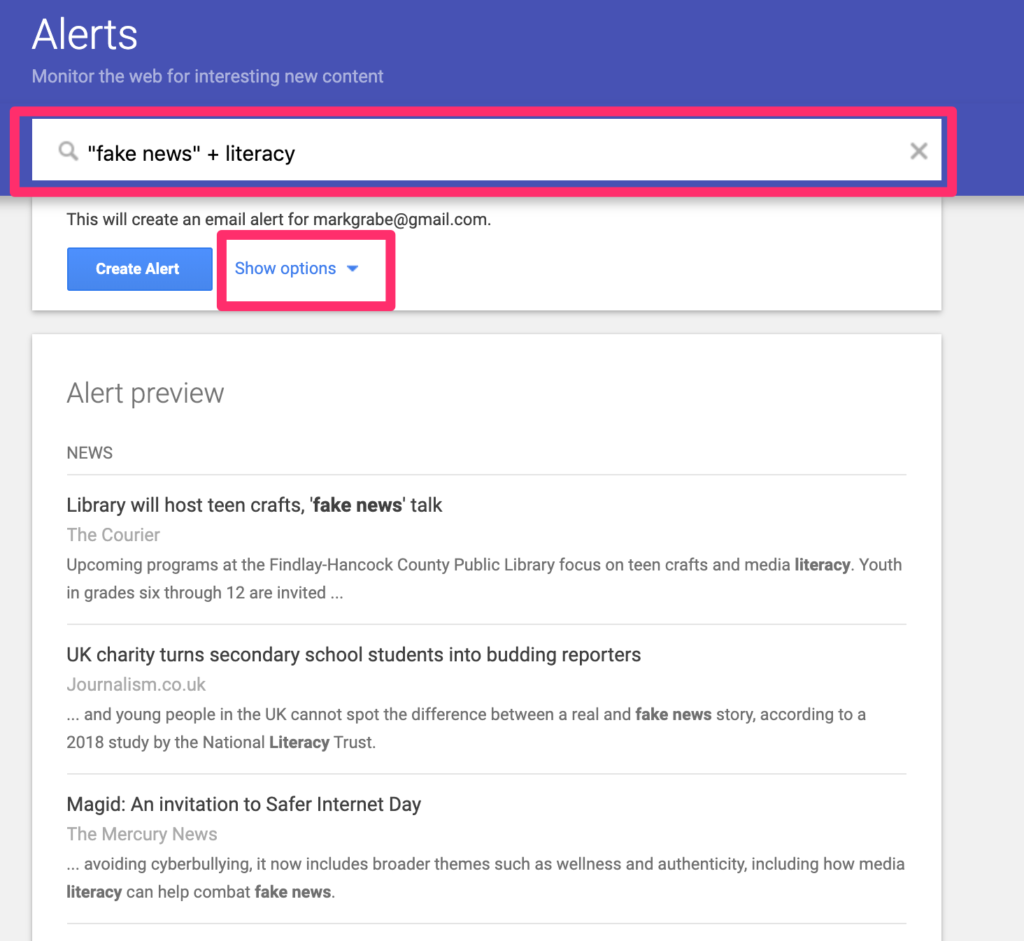
Your search to generate an alert using the same rules you would apply in implementing a one time search. Samples of what these descriptors will generate appear when the descriptors are entered. It is helpful to set specific options you would like to apply.
The following options allow a user to control parameters such as the address you would like to be used to return results and the frequency you would like to receive results.
Alerts offer educators a convenient way to follow topics on a permanent basis or for a time period during which a specific category of information might be useful. Alerts are perfect as a way to return current information relevant to a classroom project.
The following video takes you through the process I have just described.
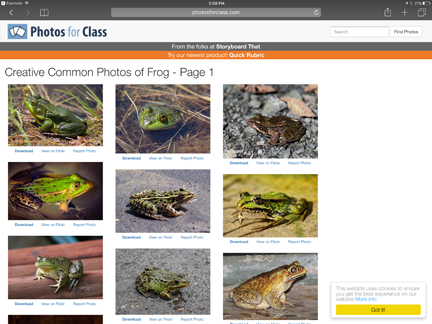
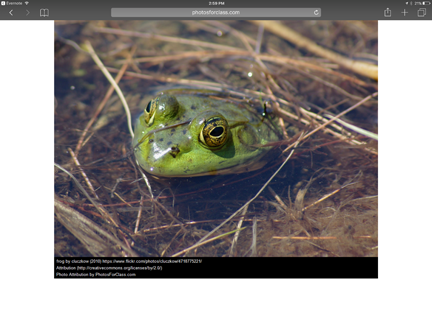
Photos for Class (Clever Prototypes) is a free, browser-based search engine for creative commons licensed images. The search service identifies images from several services (e.g., Flickr, Library of Congress). A nice feature of the service is that images downloaded are marked to include the photographer, license agreement and a direct link (see bottom of second image).
I am working on a new book that explores how tech tools can add value to existing resources. I call the approach “layering”. More about this project in a few months.
In exploring what might be coming, I have been considering what is available when it comes to augmented reality. This is adding information to what is visible in the world. The version of augmentation that offers information about a location is easy. How about adding information about unfamiliar objects.
The most basic form of information about an object would be identification. I knew that there are some services that attempt to identify images. I read that Wolfram had an advanced image identification service so I thought I would give it a try.
I admit that the following image is upside down and the image would be difficult to match to a database, but the image is not a shark.
I then tried what I thought was an iconic image from my wildlife collection.
Again, the Wolfram service was wrong, but suggested several different birds none of which were loons. It seems the Wolfram service attempts to learn from errors and it allowed me to describe the image. I hope I was helpful.
I did try the Google photo search with the loon image. It suggested it was a bird. Not that helpful.
Maybe I will have to offer examples of the futuristic stuff in the second edition.
There are multiple ways to search. Crowdsourcing search implies that you rely on the popularity of resources within a group to identify what you want to review. There are various ways to do this. For example, Nuzzel identifies links shared by those you follow on Twitter. Those links shared most frequently rise to the top and might then encourage your examination.
I use a similar approach with the social bookmarking site Diigo. In this case, I am searching the stored bookmarks of other Diigo users by frequency within a designated period of time. I use one year for most searches.
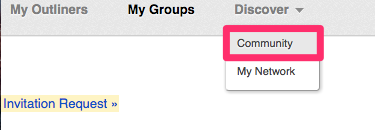
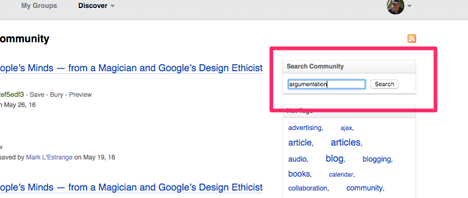
Here is the process. Under the Discover heading, use the Community option.
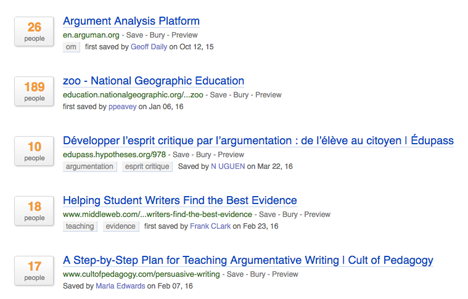
This will take you to the most popular bookmarks, but I want to search these bookmarks for a specific term. In this case, I am searching for “argumentation”.
The search returns hits on the search term. Each snippet includes other information I can use – the number of hits, the date the link was first saved, etc. I can then visit the pages, review the content, save as a bookmark in my own Diigo account, etc.
It seems to be Apple and Microsoft against Google. The “concern” expressed by the unlikely pairing of Apple and Microsoft is that Google collects, and as I understand all of the concerns, shares personal data for pay. Google, in response, argues they use the information collected as a way to improve the search experience.
While this sounds like an disagreement over a principle, the positions taken align with business interests. Google makes money from advertising. Apple makes money from hardware. Microsoft makes money from software. The income foci of these companies has evolved and this may have something to do with the positions now taken on privacy. Google offers software and services for free partly to increase use of the web and as a way to offer more ads and collect more data. Google also offers services that decrease the importance of hardware. Chrome hurts the hardware sales of Apple.
What I think is important under these circumstances is clear public understanding of what data are being collected, how it is being used, and what are the motives of the players involved. It turns out we all are also players because blocking ads while still accepting services (the consequences of modifications of browsers) involves personal decisions for what constitutes ethical behavior.
Into this business struggle and how it has been spun appears a recent “study” from Tim Wu and colleagues. Evaluation of the study is complicated by the funding source – Yelp. Yelp has long argued their results should appear higher in Google searches and suggests Google elevates the results of Google services instead. Clearly, you or I could go directly to Yelp when searching for local information completely ignoring Google (this is what I do when searching for restaurants), but Yelp wants more.
I have a very small stake in Google ads (making probably $3-4 a year), but I am more interested in the research methodology employed in this case. My own background as an educational researcher involved the reading and evaluation of many research studies. Experience as an educational researcher is relevant here because many educational studies are conducted in the field rather than the laboratory and this work does not allow the tight controls required for simple interpretation. We are used to evaluating “methods” and the capacity of methods to rule out alternative explanations. Sometimes, multiple interpretations are possible and it is important to recognize these cases.
Take a look at the “methods” section from the study linked above. It is a little difficult to follow, but it seems the study contrasts two sets of search results.
The Method and the data:
The method involved a comparison of “search results” consisting of a) Google organic search results or b) Google organiic search results and Google local “OneBox” links (7 links for local services with additional information provided by Google). The “concern” here is that condition “b” contains results that benefit Google.
The results found that condition B generate fewer clicks.
Here is a local search showing both the OneBox results (red box) and organic results from a Minneapolis search I conducted for pizza. What you see is what I could see on my Air. Additional content could be scrolled up.
The conclusion:
The results demonstrate that consumers vastly prefer the second version of universal search. Stated differently, consumers prefer, in effective, competitive results, as scored by Google’s own search engine, than results chosen by Google. This leads to the conclusion that Google is degrading its own search results by excluding its competitors at the expense of its users. The fact that Google’s own algorithm would provide better results suggests that Google is making a strategic choice to display their own content, rather than choosing results that consumers would prefer.
Issues I see:
The limited range of searches in the study. While relevant to the Yelp question which has a business model focused on local services, do the findings generalize to other types of search?
What does the difference in click frequency mean? Does the difference indicate as the conclusion claims that the search results provide an inferior experience for the user? Are there other interpretations. For example, the Google “get lucky” and the general logic of Google search is that many clicks indicate an inferior algorithm. Is it possible the position of the OneBox rather than the information returned that is the issue? This might be a bias, but the quality of the organic search would not be the issue.
How would this method feed into resolution of the larger question (is the collection of personal information to be avoided)? This connection to me is unclear. Google could base search on data points that are not personal (page rank). A comparison of search results based on page rank vs. page rank and personal search history would be more useful, but that is not what we have here.
How would you conduct a study to evaluate the “quality” concern?
I find the data generated by my web site to be very interesting. Big time web players study such data carefully in order to optimize their web business. I study such data because I am curious.
I have noticed a specific down turn in traffic lately. One factor that seems to have changed is the number of hits that result from search. So, analytics can determine the referrer for a hit and I can identify hits resulting from searches.
So why might search hits diminish (aside from the obvious possibility that I write about stuff others find less interesting). Here is something I wonder about. Can Google tell the difference between a link farm and a social bookmarking service?
One prominent variable in the Google ranking strategy involves the number of sites linking to a particular site. A simplistic way some have tried to “game” this system is to set up multiple web pages with links to other sites the scammers would like to see ranked higher in Google searches. The Google ranking model attempts to identify such artificial way of creating more links (link farms) and to discount such sources.
There are legitimate sites that consist largely of links to other sites. For example, a social bookmarking service or even a simple effort to archive useful sites as a service to others would consist of content with high link density.
One of the services on my site was developed as an open source bookmarking site. I became interested in a service called Scuttle because it allowed me to operate my own bookmarking site. It was written in php/MySQL and I spent time adding some features. I created a ranking systems based on the number of times users actually visited one of the sites listed. I also created a way for users to evaluate the sites (one time only) when conducting a search and this also contributed to the ranking.
I have had some difficulties with this site. I ended up disabling the evaluation feature and the login feature because both involved users logging in and logging in allowed users to add links I might find objectionable. There was one upgrade to Scuttle. I did not make the transition because of the changes I made to the original and the lack of enthusiasm for starting over again.
I am not trying to decide whether I should delete this service. It does generate some activity, but it also causes problems. As a hobbyist I enjoy creating resources for others to use, but I do not want my other content to go unused because the content would infrequently surface in searches. There must be a way to figure this out.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




You must be logged in to post a comment.