I have been putting in a lot of time trying to get our textbook revised by the start of the Fall semester. I have had the revisions completed for a few days and I have been struggling with formatting issues as I prepared the document for uploading to Amazon. Since we split from Cengage, we have been self-publishing for about 5 years. That story our move to work without a commercial publisher has been told multiple times, so I will not tell it again.
In preparation to generate an ebook, I read several ebooks on publishing with Amazon. If you read the forward for these books, you typically find the authors claim they decided to write about publishing in this way after publishing in this way. After having done this several times now, I can appreciate this sentiment. However, at this point, working on another manuscript is about the last thing I want to do. I did decide to offer a few comments on the process for those who might wonder what this is like.
Let me begin with this statement. I know that many folks complain about the cost of textbooks and I have a mixed reaction which I have explained in previous posts. BTW – if want to read the previous comments I mention here, you might search this blog by using the tag “book” which should be attached to this post. When a college student purchases a textbook, they are paying for many things. Some of these things they may value and some may represent what they assume are unnecessary. I suggest they keep their position and also try understanding the situation from the perspective of the publisher and author. A major factor in cost is that the publisher must make its money and cover its expenses (including the 12-14% of the price to the bookstore that goes to the author) on the first sale. This is the only one that counts for them and us. Then there are the sales expenses that cover ads, free books for instructors, and salespeople going door to door trying to push their books. Finally, there are the costs of features that make the book look pretty and perhaps more useful. Photographers, editors, and designers must be paid in addition to the authors. If you have read many Kindle books you will note that the are plain in appearance and contain even in the highest sales books from famous self-publishing authors a few spelling and grammar errors. Doing it all yourself requires time and skills that vary and are independent of content knowledge.
There are really two categories of Kindle books each with different issues. There are free-flowing and fixed-format books. A free-flowing book is what is used for text-only books (most of the popular books). Free-flowing content can be adjusted by the reader to meet the personal preferences of text size and text format. You might find you need to enlarge text to make it easier to read (I do) so with text-heavy books free flow makes sense. It creates some weird formatting problems. You might encounter a section header at the end of a page. There is probably an editors term for this, but I don’t remember what it is. Our textbook has been published as a free flowing book until today.
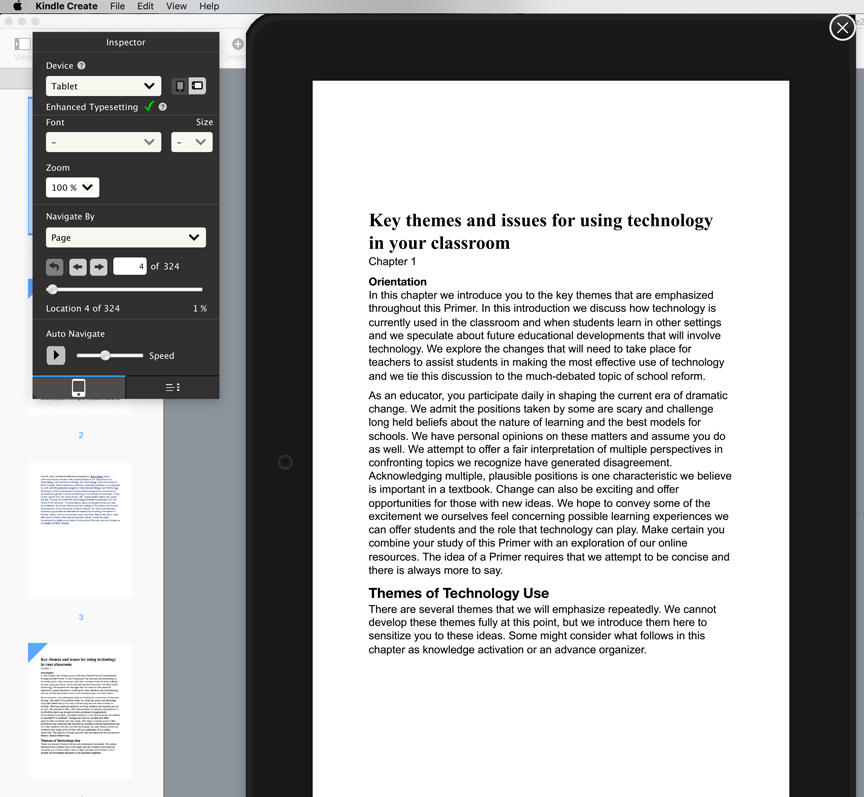
Fixed format books are better suited to books with images and graphs and tables. This is what you encounter in a heavy dosage in most textbooks. A fixed format is just what it seems – the author/editor controls the format the reader will experience. The problem here is that a fixed size page (enlarged or shrunk) is not ideal for the multiple devices and multiple preferences of readers. For example, to produce a product I like to read, I have to use a 14 point font for body text. Without this sized font, the print size that appears on a smaller iPad is just too small. This size may seem unnecessarily large on a computer where you would have the room to manipulate the size of the page as a way to manipulate the size of the print.
When you submit a fixed page format manuscript, you are basically working with a pdf within the special Kindle Create tool. Because of the way I work, I had multiple challenges getting to the stage of generating this pdf. Our textbook is a “technology for teachers” resource for teachers, but mainly written for undergrad courses that address this area. One thing I have always done is to use the same tools I suggest teachers use in my own work. So, I use inexpensive or free tools in my writing and web development activities. Amazon seems to assume authors will use Microsoft Word. I don’t own this product and although I still work on occasion for a university that would allow me to use it for free, I prefer to write in Google Docs.
I assumed I knew most of the ins and outs of working with Google tools, but did not realize that a 300 page manuscript would not be converted to a pdf when downloading from Google docs. People don’t believe me when I say this because they have created pdfs with Google docs. They have not tried doing this with a large file. My workaround sounds pretty strange, but it kind of worked. I downloaded a docx file from Google, opened it in Pages, and saved out as a pdf. Only one issue most also might not anticipate. When you cross products like this, you can encounter font substitution. Different products don’t always recognize the same fonts and when another font is substituted this can change the number of lines that appear on a given page messing up the page formatting that had been so carefully crafted. I know of no easy way to fix this issue. I used a recommended style guide for selecting fonts and font sizes, but I guess I should have used a Word book to find these suggestions rather than an ebook guide for the Mac. I scrolled through the manuscript 5 times between yesterday and today playing with page breaks before I gave up. There are still a few issues, but pretty is not my goal.
I probably started this project too late for what I ended up doing. It is interesting to watch the sales pattern for our textbook. We see single sales over the summer and then group purchases once Fall hits. I was working as fast as I could, but now these singles, some of which I assume represent profs looking for a textbook, represent the view of a dated book when a new book should be available in a couple days. This matters because in switching from a free flow book to a fixed format more appropriate (according to Amazon) for a textbook, I have to list the new book as a different book. Those web addresses instructors may have saved for the book they reviewed will not work once I see the new book is available and I delete the older book.
This is probably far more than you want to know about ebook publishing, but I thought some of the experiences may have provided useful insights.
Our newest book is now available, but it will be a week or so before you can take a peek with the x-ray view feature.
![]()


You must be logged in to post a comment.