I spent my career working in higher education and securing external funding was a fact of life in this environment. Making the effort to write grant requests and occasionally secure a grant was a part of our merit pay process. As the pressure to find funding sources to support research and research-related infrastructure and to reduce student tuition has increased, expectations have increased. In some institutions, it is a requirement to secure a certain type of grant (translate as – a grant that provides lots of overhead which is money that goes to the institution to support institutional needs, in addition, to support for the researcher) to be granted tenure or perhaps to be promoted to full professor. The differences across disciplines in the amount of this type of money that is available makes this a very unfair practice, but this is a topic for a different discussion. Let be sufficient to just state that profs in higher ed are frequently expected to secure external support for their work.
What about K-12? While the pressure is far less, K12 administrators and educators may search for funding sources beyond those available through their schools. There are grants. Most of these grants target specific goals and depending on the needs that exist within a given school, the likelihood of being funded is heavily influenced by whether a school has the need the grant was designed to address. Most grants at this level are far less competitive than the grants in higher education, but someone must do the work to apply and there is no guarantee that funds will be available for all who might qualify. Larger districts often have an individual responsible for responding to this type of opportunity and it might be an administrative responsibility in smaller districts.
There is a second type of external funding that might be described as “crowdsourcing”. In higher education, the crowd being approached tends to be the alumni of the institution. In K12, it is likely to be community members and even others interested in supporting needs which they find important. The Internet provides an increasing number of ways in which such appeals might be launched. Again, my experience with crowdfunding has been in higher education and I know that any efforts we might want to make to solicit funds from our alumni required that we go through the alumni association. Our efforts had to first be cleared with university officials to assure that our requests were consistent with university priorities.
K12 educators have multiple online services that provide a way to solicit funds (this article from EdSurge offers an in-depth summary of this issue in K12). This article identifies issues related to crowdsourcing and the opportunities for educators. Many public K12 institutions are underfunded and crowdsourcing offers individual educators a way to secure additional resources for their classrooms. Whether or not requests made by individual teachers meet district priorities is an issue similar to what I have described in higher education. Individual differences in opportunities for learners created by such funds across classrooms is another issue. Are educators expected to secure funds to create needed circumstances in their own classrooms? From a broad view, do the successful crowdsourcing efforts of some teachers relief the public of their responsibility for public education.
Some of the following content first appeared on my travel blog – grabetravels.blogspot.com. Here I have appended additional content explaining the educational potential of using identification keys and apps for identification of plants and animals.
———–
For anyone from the midwest, photographing the flowers of Hawaii becomes a constant activity. The flowers are everywhere even this time of year and they are truly beautiful. At some point, you exhaust yourself on the artistic value of your growing photo collection and you start to think beyond the vibrant colors and the huge blossoms. You begin with simple questions. I wonder what this plant is called? You may wonder about other things as well. How does this flower grow in the crook of this tree without having roots in the soil?
I started mixing tech with photography a long time ago. My biology background even plays a role in both my plant photography and my interest in technology. I began exploring apps on my phone that claimed they could be helpful in plant identification. Point your camera at a plant and the app would tell you what that plant was and direct you to additional information about the plant. I have read about face recognition and the role artificial intelligence plays in making this possible. It made some sense that the same technology might be applied to plant identification.
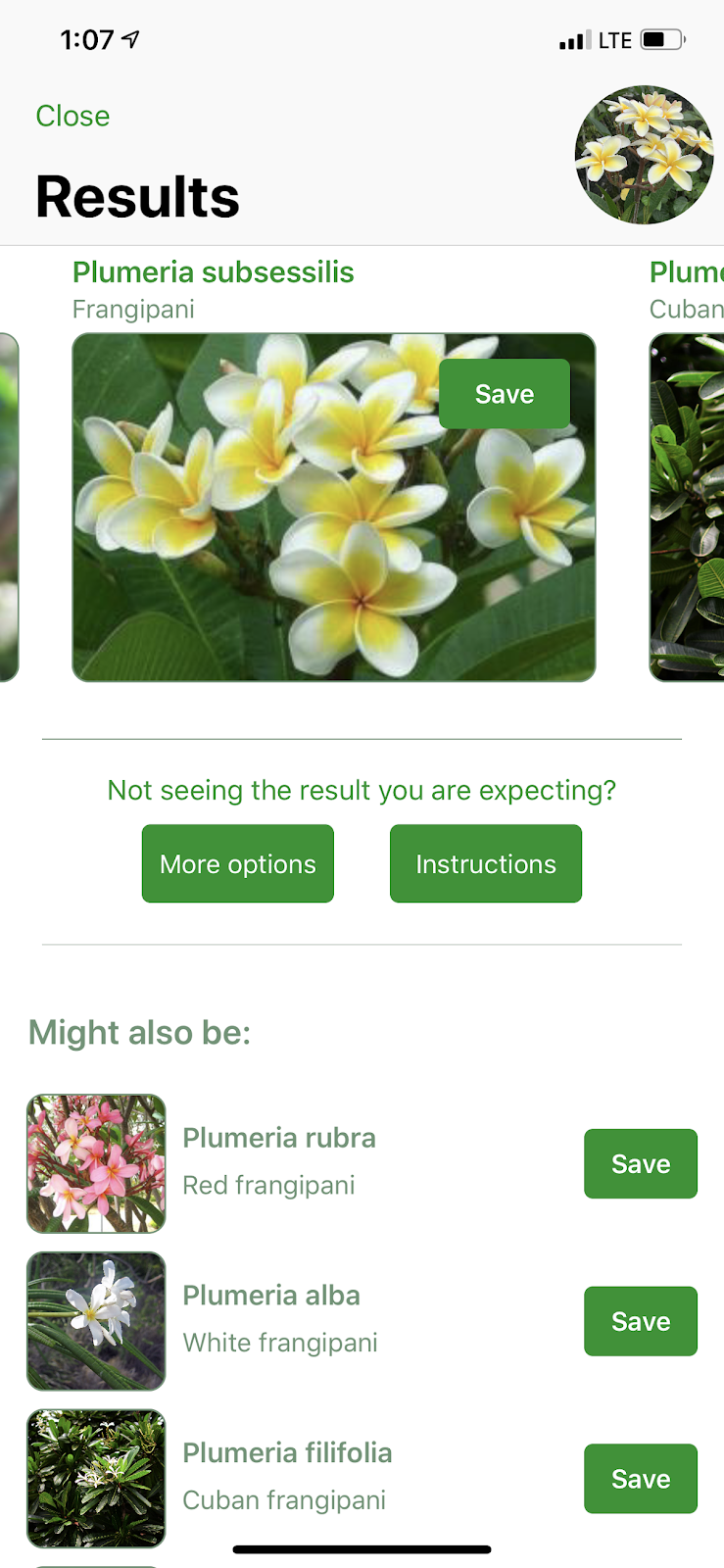
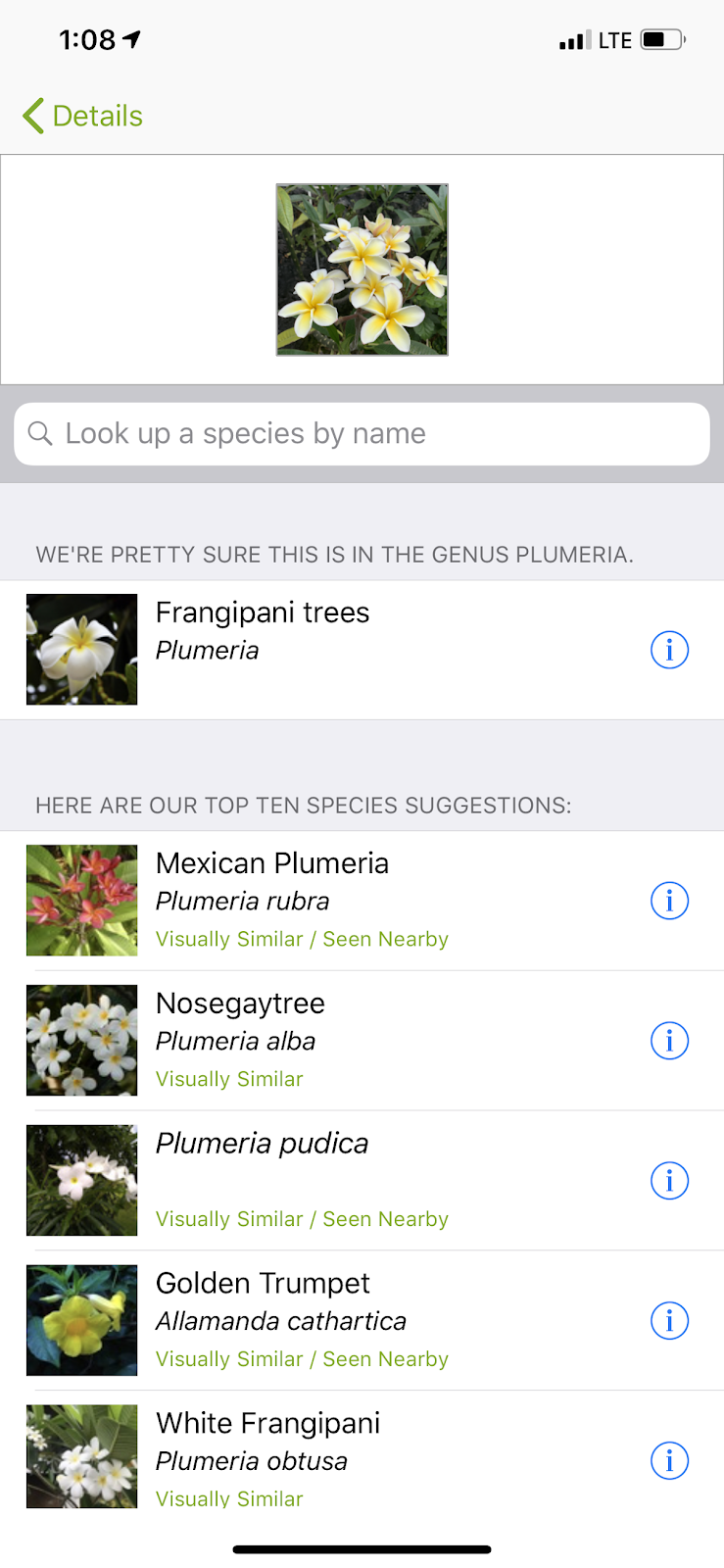
During last year’s visit to Kauai, I explored an app called PlantSnap. This year I added iNaturalist to my app collection. Both work in a similar way. You take a photo and the app makes a guess as to what appears in the photo. The app also offers some other possibilities and relies on you to evaluate the first choice and the alternatives. If nothing makes sense, the app farms out your photo to the public that follows the app to see if anyone has an idea. Selecting a choice offers a way to get additional information.
Evaluating these apps presents a problem. You must know what you are looking at in order to determine if the app made a correct identification. Here are three photos I took walking home from the coffee shop and the top choice offered by each app.
[PlantSnap]
[iNaturalist]
[PlantSnap]
[iNaturalist]
[iNaturalist]
I know both apps were correct with the genus. I am not capable of evaluating the accuracy at the species level.
There are other ways to do this. You can purchase a plant identification book. There are even online keys that offer an identification approach based on color. I have decided the flowers are probably easy, but I wonder what happens when the app is asked about a plain green plant. I don’t have any examples and I am not certain I would be able to check the responses, but I have a few more days here and plenty of specimens I can photograph.
There may be no post tomorrow. We have to move out of our condo and into a hotel. Two of our kids and their families did not have a Spring break option during the two months we originally booked so we had to find a way to extend our stay. I hear there is still snow and flooding in the midwest so this has worked out well.
I started my career as a biology major and the preparation to teach biology in high school. My interest in science education and learning (and the army) led me another direction. Many of my original interests remain and pop up in some of the things I write.
Some of my zoology, entomology, and botany courses required that I identify specimens in the field or lab. To make these identifications, we were taught to rely on dichotic keys. A key works something like a “choose your own adventure” story. Instead of a segment of text that ends with a decision point offering options and the option selected determines the next segment of text read. In an identification key, the key asks the user to make an observation to answer a dichotomous question – do smaller branches appear along a larger branch opposite each other or from alternating sides of the larger branch? Depending on the option that applies to the specimen to be identified, the user is sent to different follow-up questions. Eventually, the process arrives at what the key assumes is the species to be identified. Creating such a process would obviously be a tremendous challenge, but for the user a key offers a practical way to make an identification. Note that a key works in a different way from the identification resources you might purchase to identify birds, wildflowers, insects, etc. A key is supposed to be an algorithmic as opposed to a heuristic approach to solving a problem.
Identification of an unknown is a skill one learns in several sciences (e.g., geology). Exploring the process of identification using several approaches would make a great biology lab. Bring in several “mystery” specimens and have students use a key, an identification book, and maybe an app to see what they can accomplish (here is a simple online botany key). A good related exercise is to consider what the might be the advantages and disadvantages of the approaches I have identified.
Surveillance capitalism, a term popularized by economist Sashona Zuboff, describes the collection of information about people for the purpose of economic gain. Zuboff’s work focused on surveillance capitalism as it was practiced by social media companies paying particular attention to a) user lack of understanding that information about their online behavior was being collected and integrated to the extent that was the case and b) the effort of companies to provide online services in such a way that users would be more committed to the service and provide more behavioral data in the process.
I have no training as an economist and I likely misunderstand many of Zuboff’s interrelated arguments involving economics, the psychology of confirmation bias and behavior modification, legal issues associated with informed consent, and factors such as the “network effect”. I do have some experience offering online content complete with ads and I have some experience applying both ad blockers and coding that enables the identification of ad blockers. I also have some experience making use of online services that are attempting to implement other approaches to collecting and sharing revenue for online services.
I would describe the question I am attempting to answer as this – Can capitalism offer an effective alternative to surveillance capitalism or will the greed of some online companies eventually lead to government intervention? I suppose the answer to the question could be other than the two options I identify, but I am betting things will go one way or the other.
The use of an online social media service involves the interaction of 3 and perhaps 4 parties: you as the user, the content creator, the service (e.g., Google, Facebook, Blogger), and possibly the company offering an ad (actually a combination of the company advertising and the ad delivery service). Each party has costs and benefits in the interaction of these agents. In the most common present model, a user makes the attempt to use a service – e.g., read a blog post on Blogger. The user reads content on this service for the cost of providing personal information collected by the service (Google). This is the cost to the user. The service (Blogger a service of Google) has the potential of receiving revenue for the cost of providing the infrastructure through the collection of personal information and possibly through ad revenue generated from clicks of ads. The ad company the infrastructure company for ads clicked is compensated by those who want ads to be viewed. The content creator is compensated for their work (their cost) in creating content when an ad associated with their content is clicked. This is a balanced system or at least it is proposed to be so.
Consider what happens to the present system when one of the parties involved finds a condition as it exists unfair or devious. This would be the case when users (viewers) of content within this system object to surveillance capitalism because they find the cost to them of revealing their personal information out of balance with what they receive. They might decide to deploy an ad and cookie blocker to reduce the personal information that is revealed. This does prevent the infrastructure provider from receiving the benefit of the information harvested and any funds provided from ad clicks. This means the infrastructure company is providing a free service and still must pay the costs of providing the infrastructure. Likewise, the content provider continues to spend the time (a resource) involved in generating content and receives no compensation for this labor and the ad company receives no income because no ads are viewed and clicked. In solving the problem of unwanted surveillance, the user has defunded all of the other parties involved and in the long run this will likely have consequences. For example, the infrastructure company could block the reveal of requested content to users blocking the accompanying ads. Content creators could look for other outlets for their content or at least reduce the amount or quality of the content they produce.
Are there solutions existing or new companies can apply to bring these parties into some fair balance? I think some serious efforts are starting to emerge.
First, there is the subscription model that has been successful with streamed music. Some of the same companies now focused on music are expanding their model to include podcasts. To access podcasts affiliated with a service, users will have to pay the price of subscription. In some cases, this could mean the subscription they pay for music would also include podcasts. Content creators would be paid a small amount for each time their podcasts were served. This model could be extended to other content types – e.g., Medium for written material. What seems to be happening at present is that the more popular creators are compensated and those who receive less attention can offer content but are not compensated.
A second service I think has great potential is the Brave browser [https://brave.com/]. You can download this software for pretty much any device. The browser is really part of a service that involves three capabilities. First, the browser blocks cookies and scripts. This capability can be controlled by the user as a general approach (everything is blocked) or as a blocking capability turned on and off depending on the site. Second, the more general service associated with the browser allows users to commit an amount of money that is distributed to content providers/services in proportion to the amount of time allocated to the sites visited. Content creators must enroll (no cost) to be compensated in this manner. Each month, the sites visited are listed for the user and the user can drop for compensation any site from the list. Money is not forwarded to sites until they register. Finally, the service is just rolling out a potential compensation opportunity for users. This approach substitutes ads through the Brave browser service for ads normally accompanying the content when viewed with other browsers. So, users are paid to view ads, but the data normally collected via cookies and scripts are not allowed to pass. This final component of the Brave model is just being tested at this time. Brave takes part of the ad revenue when users offer compensation for content/service and when companies offer ads through Brave. These funds provide compensation for the infrastructure and company.
So, there are multiple opportunities here (as I understand the possible combinations). Users could use Brave to block ads. Users could contribute and block ads. Users could receive compensation for viewing ads and block ads. Users could blocks ads, contribute, and receive compensation for ads viewed via Brave.
Again, it is possible to consider how the user, content creator, and infrastructure provider are compensated when thee different combinations are implemented. If a user blocks ads and nothing else, the user receives content or uses a service at no cost, but the content creator or service provider is not compensated. If the user blocks ads and submits a voluntary contribution, the user receives access to the content or service and the provider is also compensated. If the user blocks ads, but accepts user ads and offers no compensation, the user benefits in multiple ways (content and revenue) and views ads and the providers receive some compensation. The difference in this final combination from the most common existing experience is that the user views ads, but does not provide personal information that can be shared.
I hope that I am understanding the Brave long-term view appropriately in claiming that the content creator potentially receives revenue from both contributors and from ads shown by Brave. It would be possible to compensate users, but not content creators when ads are displayed.
If Brave gets their approach off the ground and attracts sufficient users, I predict the model will change such that content contributors will make an exclusive commitment to have their content viewed through Brave and users will have to accept viewing ads for these sources unless they are contributors. This would guarantee a revenue source for users and content creators. Note – I am guessing at a long term model here. If this should happen, I would also predict that a similar model would then be adopted by other sites such as Facebook and Twitter. Google would be most harmed by this model because they would then be in competition with Brave to make money by selling and displaying ads.
In summary, I see alternatives to surveillance capitalism should these competitive models take hold. The present surveillance capitalism model is still much more popular, but public awareness of the collection and sharing of their information is encouraging ad/cookie blocking. Should ad and data collection blocking become common, the lack of opportunities for certain categories of content and service creators will eventually extinguish their willingness to work without compensation.
If capitalism doesn’t take on surveillance capitalism, government intervention seems very likely.
The following comments are based on a recent book by Lee McIntyre – Post-Truth. I suggest it as a useful read for any educator interested in information literacy, science denial, and similar topics. I think it supports my observation that teaching students to evaluate the credibility of the online resources they encounter is not enough to assure they develop an accurate representation of their world. A broader approach to online literacy is required. This book offers some suggestions, but it is possibly more useful in identifying the multiple factors that have created the present information environment in which we presently function.
I will not attempt to write a summary of the multiple issues McIntyre’s book identifies. The resulting text would be far too long for a blog post. I will attempt to identify some of the key factors the book identifies as I interpret them. The result is more an outline of factors than a complete description. When I offer my own observations or comments, I will do so within brackets so my ideas can be differentiated from by summary of the author’s comments.
Factors creating the Post Truth environment:
Personal factors – Asch conformity [influence of group position], confirmation bias [Author seems to propose a brain predisposed to support existing personal perspectives – I see as a constructivist model of learning.]
Decline of mainstream media due to decline in ad revenue and readers/viewers going elsewhere, financial difficulties result in decline in number of actual reporters, decline in shared information experience as readers/viewers do not have a common information experience.
Rise of 24/7 news, much more time spent on opinion relative to actual news, embrace of a perspective/bias, encourage interest/viewers through promotion of conflict. Presenting both sides of a story when one side has little credibility confuses viewers and feeds personal biases – objectivity should not be confused with objectivity.
Social media – selection of friends, bias in what friends share, bias in what service feeds reader to suit their values
Weak approach of formal science – science is always questioning and suggesting more research would be helpful. Misleads public as to what is known because of this cautious approach.
Generation of purposeful falsehoods likely to be embraced by target group. Falsehoods given greater reach by sympathetic audience and bots.
Some ideas regarding what can be done
One remedy is heterogeneous group interaction – develop an appreciation for the scrutiny of others [This fits the value of argumentation]
Important to call out, rather than ignore lies no matter how obvious the falsehood.
Invest in a quality news source. Free is not free and not suited to meaningful learning.
I am now retired, but I still enjoy the beginning of a new semester. Every few days or so I check Amazon to see if anyone has purchased our textbook. Sales are nothing like earlier times when we were selling an expensive paper version through a publishing company, but the present circumstances are more about feeling relevant.
Our transition from big publishing company to self publishing was originally motivated by our interest in a different model for the college textbook. The motive was partially to offer a less expensive textbook (I called it the $29 textbook project), but also to offer a different approach more suited to the content – technology in education. We thought it ironic that our orignal project sought to develop classroom technology integration skills in educators using a book. We wanted both to differentiate the content sources by creating a primer rather than a book for more static information and web content to improve the recency of information and to offer actual demonstrations and examples. We also thought it made more sense for authors to write continuously rather than intensely once every three years. We went back and forth with our publishers for several years and could never get to the point of implementing our project. Book companies see efficiencies in using standardized tools and approaches. For example, they wanted to offer professionally shot and edited videos of a topic such as problem based learning they could use in several of their education books. These videos would not necessarily involve technology. We wanted to offer videos of the problem based activities featuring the teachers who implemented them we used as examples in our book. We wanted to create the opportunity for the educators who adopted our book to share among themselves. For example, we were promoting the idea of an “interactive syllabus” – just a web page serving as a course syllabus and linking to tasks and resources used to augment assigned readings. There is no reason to treat the book authors as the experts when profs and students have their own experiences and tasks that could be shared to our Primer.
Eventually, we agreed our priorities were not compatible and after 5 successful editions we were given full control of the copyright on our book to do with what we wanted.
So, we became self publishers and have tried to offer a scaled down version of some of our ideas. We went from selling a $140 book receiving royalties (12% on the wholesale value) to a $9 book receiving 70% minus a fee for the download size of the ebook. The one frustration we have is that while we get instructors adopting our bookis limited and while we don’t know for sure the activity associated with our online content seems unrelated to use of the book. For example, one would expect to see content associated with early chapters to be used early in a semester and indicators of this nature. We can only guess at why this is the case because we really don’t have a way to ask the adopting profs as would be the case with the book reps who make contact with profs for the commercial textbook companies. I still think the diversity of resources and a closer link between book and supplemental content are good ideas, but we have found over the years that it can take time for new ideas to be implemented.
I have been reading a lot lately about computational thinking and trying to decide what I think about this concept and trying to decide exactly what I think it is. To be clear, computational thinking as an educational goal and learning to program as an educational goal should be differentiated. “Should” is my opinion, but I think it is fair to suggest that as goals these concepts are about accomplishing different things.
My thinking on “computational thinking” goes back a long way. I read all of the Seymour Papert books and included a chapter on programming in the book my wife and I have written for many years. I understood that Papert had a broad vision of what programming could accomplish, but I also read the research challenging the position that programming experiences provided as an educational activity accomplished what I now see described as “computational thinking”. It is not just me that is making this connection (see this recent description of Papert’s work) and it is not just me that thinks the “coding to develop skills other than coding skills” is not really that well supported.
In thinking about the recent resurgence of the notion that learning to code offers broad benefits, I have identified what I see as important and interrelated sub-issues. The first is whether a notion such as computational thinking adds anything to the existing prioritization of “higher order” thinking skills. I guess when you get right down to it, both computational thinking and higher order thinking are abstract and likely are interpreted in different ways by different people. The issue is that it seems to me administrators and practitioners buy into a simplistic version of “computational thinking” not necessarily and hopefully not intended by the theorists/researchers and maybe even the evangelists promoting this cause. This simplification may encourage an unsuccessful implementation because the intended approach has been simplified in a way that the intended skills are not developed and not even taught.
I have two issues related to implementations of what Papert decided to call “constructionism”. Note that constructionism as a philosophy/learning theory or whatever it should be called is not the same as constructivism. The constructs can be related, but constructivism is broader and has a different focus. Constructivism argues that individuals create their own understanding. This is mental activity and exactly how this works is vaguely defined beyond suggesting that learning amounts to bringing external experiences in contact with existing knowledge potentially resulting in the modification of existing knowledge. Simply put – bringing together amounts to thinking. No one can think for you hence you ultimately learn only if you make the effort to think. Constructivism avoids the details. I rely on the understanding of thinking as cognition to handle the details. I don’t see cognition and constructivism as necessarily at odds.
Constructionism (Papert’s idea) emphasized external building (coding) to influence internal thinking. What counts as external building is unclear to me. Those promoting the broader concept of making expand the notion. I also think it obvious that external activity does not necessarily equate to productive thinking. You can certainly have thinking without building (I hope you think when reading this post) and you can have building without thinking (my favorite example if the amount of chemistry we learn from baking).
I have two questions when I think about constructionism and computational thinking.
Question 1: Are these skills and the suggested methods for developing them really new? I don’t think I really know, but I have an opinion. The question matters because we should not be starting over if we already know important things about what it takes. I apply this question in considering two concepts – making (Papert’s constructionism) and computational thinking.
The maker movement reminds me of all of the past work on generative learning. Generative learning was a broader concept (in my opinion) suggesting that it may be productive for some learners to be engaged in external activities to encourage productive thinking behaviors. For example, if learning results from the integration of existing knowledge with new information/experiences, we have long asked learners questions to encourage them making the effort to find such a connection. Being prompted with a question may seem very different from making the effort to create a program to make the computer do a specific thing, but both are external tasks hoped to encourage productive mental behaviors. What have we learned from research on many types of tasks about when the tasks are actually generative and when they are not?
Higher order thinking is not new. Problem-solving as an example is not a unitary process. Many efforts have been made to identify the components of problem-solving, to propose how these components skills might be developed, to evaluate whether these efforts to encourage learning tend to be successful, and whether development in one domain transfers to others. Note that the argument for developing computational thinking for all assumes transfer. It is more than developing programming skills. It seems to me that the subskills and dispositions associated with computational thinking have yet to receive nearly as much attention as that devoted to problem-solving, but I see planning, understanding that debugging is not failure, abstraction and instantiation, problem identification and problem-solving frequently mentioned. Are these skills unique to coding and is coding really the most efficient way to develop these skills within the school environment. Do we know anything that is relevant from past work?
Question 2: Why the enthusiasm for unproven ideas (coding to develop computational thinking, computational thinking as unique from other ways to describe higher order thinking) and why the superficial attempts to implement?
Regarding the enthusiasm for these “new” ideas, here are a couple of ideas that may apply to administrators and classroom educators.
I have been reading Dan Lyon’s recent book Lab Rats . The book criticizes the misapplications of processes and ways of thinking that have resulted from the digital economy. One of the issues Lyons focuses on is the willingness of management to move from unproven practice to unproven practice resulting in serious disruption to organizations and to employees. Why? Lyons proposes that these companies exist within a fearful environment. Change and competition produce uncertainty and fear of what the future might bring. There is this sense of urgency that something must happen making decision makers easy prey for evangelists touting this or that new approach. At least trying something new gives the impression of doing something.
My second thought might be described as “who sweats the details”? A related position is that we all sweat different details. Careful reading of Papert or Aspinall (a new computational thinking evangelist) and the existing relevant research should indicate a careful and realistic picture of what classroom application would look like. I have had the time and the inclination to review this content at this level. I can sweat these details as a function of my professional responsibilities. Few classroom teachers can make this commitment because they must sweat other details. The danger that can result from these different emphases is that there is a resistance to considering what these two different professions require (academic and practitioner) and a reluctance to appreciate what each offers. I don’t pretend to be able to tell a fourth-grade teacher working with a group of students I have never met how to do many things teachers must do on a daily basis. However, I feel perfectly justified telling this teacher that a couple of experiences allowing students to explore Scratch or Ozobot programming will result no benefit to higher order thinking. At best, I think I could explain the basics of the experiences that might have a chance of being successful, but even then I am doubtful of transfer to most “problem solving” tasks these students will encounter. The teacher would then have to decide whether he/she feels it practical to make adjustments necessary to meet these basics.
Is this egotistical? Some might think so, but I think it reflects an honest description of what different professionals have committed to do. There would certainly be exceptions, but individuals would need to be brutally honest in considering whether they qualify as an exception or not.
I wish I could convey my opinion on this topic in a way that is both concise and persuasive. I just don’t think I can. Part of the problem is that the way so many educators think about computational thinking, if they think about it at all, is part of a bigger set of topics that includes coding, computer science, STEM, occupational preparation, and equity of who can eventually take advantage of the occupational opportunities of working with technology. I have different opinions about many of these topics in isolation, but too many in my opinion see the topics as tightly integrated. Second, I question what many understand computational thinking to be and exactly why they think it is valuable. How specific of a description could you provide?
I have this mental image of a fourth-grade teacher engaging her class in an hour of code activity suggesting to parents that these students are being prepared for occupations of the future and are simultaneously developing valuable computational thinking skills that are helpful in many aspects of life. It is my opinion that this educator while unable to write code herself or himself is aware that digital technology relies on code that someone has written, that someone must have the skills to write this code, and that there are many many vocational opportunities for those with the skills to write code. More important to this blog post, the notion of computational thinking is not something the educator can really describe, but this type of thinking is evidently potentially of value to the improvement of performance in other academic areas and eventually when developed in many areas of life. Somehow computational thinking, whatever it is, can be developed through learning to code and these brief activities arranging blocks representing commands that control the dancing cat on the screen are making a contribution to this learning.
I, in no way, am demeaning the capabilities of this hypothetical educator. I am attempting to describe what I think is a very common situation. I admit despite purposeful attempts to read the literature on computational thinking going back to Papert’s works and the careful research on just what students learning to program in LOGO learned and despite thousands of hours writing code myself that I find myself in a somewhat similar situation.
I can point interested parties to definitions of computational thinking and to “standards” intended to identify what must be developed to advance this capability. I will provide what I think is a nice source shortly. I think I understand what at least some of the skills and dispositions described as components of computational thinking are and I recognize the presence of examples of these components in various advanced academic domains.
So, for example, computational thinking involves developing and thinking in terms of abstract, multilayered models. These models are descriptive at one layer, but link to actions (code in the case of programming) and data at other levels. By my understanding, you see examples of these multilayered models in:
You see methods for testing models in statistical procedures such as path analysis and structural equation modeling.
You can work through this type of exercise yourself if you are trying to understand how to see the presence of some of the components of computational thinking in other areas.
It is not that I don’t see the value in learning many of the skills and dispositions frequently described as computational thinking. It is not that I don’t see the skills and dispositions as important to coding. So, what is my hangup?
Let me start this way. I have just read a report from a group that has labeled itself as Digital Promise entitled Computational Thinking for a Computational World. This report is obviously pro computational thinking. The report goes through the traditional arguments for programming – there are lots of jobs and technology is and will increasingly play an important role in all aspects of life. Then, the authors add an argument based on computational thinking. In support of the general utility of computational thinking, the authors differentiate coding (the specific skill of programming), computer science (coding plus other issues such as ethics, social impact), and computational thinking (the thinking skills and dispositions programmers apply in programming). The present these three topics as a Venn diagram both to argue that they are interrelated, but also independent. So, the thinking skills and dispositions used by programmers have broader utility than just to be used in coding (I guess this is the intent of showing that the circles representing computational thinking and coding are not the same circle.) The leap of logic that is encouraged is that coding and computer science encourage the development of these thinking skills and dispositions that have this broader utility. As a psychologist, I am most familiar with labeling this final claim as transfer.
I will return to the question of transfer at a later point.
Perhaps I can do better than use descriptors such as thinking skills and dispositions. There are plenty of examples of other writers making the effort to be more precise in identifying these components. One of my “go to” efforts of this type is provided by the paper entitled “Demystifying computational thinking” by Shute & colleagues (2017). The authors do a nice job of describing the historical background of the effort to identify these components, points to a number of efforts to do so, and offer their own list.
The authors do one other thing I believe is helpful. Again using a Venn diagram, they identify the overlap and uniqueness of computational thinking and the thinking required in another discipline (math). It was this Venn diagram that offered a way to think about my core concern with the emphasis being placed on computational thinking. If thinking skills and dispositions transfer (a complex topic itself), what is unique about the skills involved in coding. Why is coding better than any other domain in which abstraction, model building, testing models against data (experience), modification of approaches when this match is not particularly good (debugging), etc.? For example, how is computational thinking different from whatever one would describe as the collection of skills and dispositions involved in writing? Writing has the advantage of being an important life skill and a generative activity fairly easily adapted to the processing of information and the externalization of the cognition associated with procedures involved in most content areas (writing across the curriculum). Admittedly, writing activities may not presently be implemented to these ends, but why retool to a new area of emphasis, coding to develop computational thinking, when improvements in enhanced writing opportunities, say multimedia writing to persuade, to analyze, and to explain, could offer a more efficient way to develop similar thinking skills and dispositions. Wouldn’t the professional development necessary for teachers to make more effective use of writing as writing to learn be easier to implement than the professional development necessary to prepare most teachers to use coding to learn. Maybe writing across the curriculum needs a similar catch phrase that implies similar benefits to computational thinking. Writing across the curriculum may just need a new marketing campaign.
I suppose one could argue that the overlap in skills noted by Shute and colleagues offer a different insight. Wouldn’t it follow that skills developed through coding also apply in math? Perhaps, but since math is already taught through multiple classes why add an independent and additional way to develop these core skills. Second, see the comments on transfer that follow. A preview – skills are not skills. The version of problem-solving developed through programming is not the same as the version of problem-solving developed through learning and applying math.
A few words about transfer. First, the expectation that general, higher level skills can be developed sounds great, but is very challenging to get done. Problem-solving or critical thinking in one content area do not automatically work in another area (Perkins & Salomon, 1989). It is not that skills developed in one area cannot offer an advantage when encountering what could be similar situations in another area, but that certain conditions must be met to make this transition likely. Perkins and Salomon (Salomon & Perkins, 1989; Salomon & Perkins, 1989) describe a couple of ways to accomplish this goal they label high and low road transfer. Low road transfer takes a lot of time and varied experiences likely impractical in K12 settings and high road transfer requires mediated experiences (instruction) most educators would find they were unprepared to provide. Just to be clear, the ideas advanced by Salomon and Perkins were based on their careful analysis of efforts to demonstrate transfer for students exposed to LOGO programming.
So, what is my present thinking.
First, programming is a valuable vocational skills and the opportunities to explore should be made available. There are challenges. Most programming courses are AP courses and this does not seem like it makes sense as a “coding for all” opportunity. Fitting programming courses into the curriculum in many schools is a challenge and many states do not allow a programming course to count toward math or science requirements. Then, there is the challenge of finding educators with the background to teach these courses. Given what is required for far transfer, skilled instruction is necessary. If we are serious about this area, addressing some of these challenges should be a first step.
The question of which skills and predispositions are developed by which tasks is even more complicated. At present, I don’t see a unique benefit for computational thinking as distinct from other generalizable thinking skills and dispositions that have a history of being developed in other more convenient ways. I could be convinced I am wrong, but I don’t see the research to make this case at present.
Resources:
Digital Promise (2017). Computational thinking for a computational world
Perkins, D. N., & Salomon, G. (1988). Teaching for transfer. Educational leadership, 46(1), 22-32.
PERKINS, D., & SALOMON, G. (1989). Are Cognitive Skills Context-Bound? Educational Researcher, 18(1), 16–25.
Salomon, G., & Perkins, D. N. (1989). Rocky roads to transfer: Rethinking mechanism of a neglected phenomenon. Educational psychologist, 24(2), 113-142.
Shute, V. J., Sun, C., & Asbell-Clarke, J. (2017). Demystifying computational thinking. Educational Research Review, 22, 142-158.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.