One of my broad personal interests has long been how what might be described as digital tools can facilitate human cognitive tasks. Many of us might accurately be described as knowledge workers. What this work involves varies with occupation and avocation, but, by definition, our work largely depends on cognitive (thinking) behaviors. The cognitive tasks that are employed vary in type and frequency of application across categories of knowledge workers so it follows that the ways in which technological tools might be of value will vary as well. I happen to be an educator.
This was perhaps a long way of setting up my argument which involves the application of AI. We are at a point of discovery when it comes to how the recently available AI tools will be of value in the many specific niches in which AI may support us. I am past the point of worrying about whether AI tools are a problem for education and the discussions of how potential problems might be countered. This took about a week. Our new reality seems obvious as AI tools for research and content production now seem to be arriving daily. It seems obvious we should commit to a period of exploration and evaluation (formal and informal). I think this is what OpenAI was hoping for with the release of ChatGPT. What creative uses will emerge and how well do they seem to work? In what specific aspects of work do these tools as they exist in their present form offer functions that can be identified and shared? Worrying about evaluation and control can wait until we have more experience.
I have an example of what I mean by a niche. The example may or may not be something you relate to in your own situation. If it fits, great. If not, consider it an example of the type of problem identification I think is valuable in searching for applications of a new capability.
One exploration
As a writer for a specific community (educators interested in what research might say about practice), I do and describe some of my own research, but I also spend a great amount of time combing the published literature for studies that might be relevant to what I describe for others. Like so many areas of the sea of information that could possibly be examined, what might be relevant to my interests is immense and growing and quite challenging to explore. It gets more challenging. The research in areas that involve human behavior is very different than say research in chemistry. Human behavior seems more messy and complicated and you encounter bodies of work that seem on the surface to be very similar and yet produce inconsistent and sometimes contradictory results. Those who don’t go deep can easily make pronouncements based on a given study that someone else can challenge based on a different study. It is frustrating to those of us who do this work and I am certain even more frustrating to those who consume our work only to find that what we propose can be questioned.
Here is perhaps an easier way to explain at least part of my challenge. On any given topic (e.g., Should students take class notes in a notebook by hand or using a laptop or tablet), there are both studies asking this straightforward question and there are studies dealing with the underlying mechanisms. Since straightforward comparisons often generate inconsistent results, a careful knowledge worker must review the method section of the studies carefully to try to identify differences that might be responsible for the inconsistencies and then try to locate other studies that may bear on the importance of differences in the methodologies. You find yourself trying to make a simple decision facing maybe hundreds of documents that may each take an hour or so to carefully review.
So let’s start with the task of identifying the potential group of studies that may be relevant and making the decision of which of these documents should time be invested in reading. It may seem a small thing, but we may be making decisions that could easily impact days of labor.
Stages in useful content identification
My workflow typically follows a three-stage process.
- Identify potentially relevant papers
- Evaluate papers to determine potential
- Read papers
Stage 1
Most folks who have a content location challenge probably now assume a Google search is how to proceed. I tend to work a little differently. I usually begin with a credible source familiar to me. I examine the reference section of this source, but I also use two online services. The reference section identifies studies cited by the author(s) of the paper I have already found valuable. These papers are older, but may identify studies producing conflicting conclusions or complementary studies using somewhat different methodologies, different participant populations, or other potentially informative variations.
I then enter the title of the paper into one of two search services – Google Scholar and Research Rabbit.
Google Scholar extends the value of the existing list of resources I am now aware of in a forward direction. In other words, it lists other later studies that have cited the study I started with. Using Google Scholar I can review the abstracts of these later studies and perhaps find other relevant studies.
Research Rabbit extends the power of Google Scholar in both directions. It moves both forward and backward and forward for multiple “generations”. These data are returned as individual abstracts and citations, but also as a graph showing additional interactions. By “seeding” the service with several related papers it is possible to identify papers that are commonly cited together which are then proposed as being of greater value. The following image shows an example of a graph (red box) for the paper I am using here as an example.
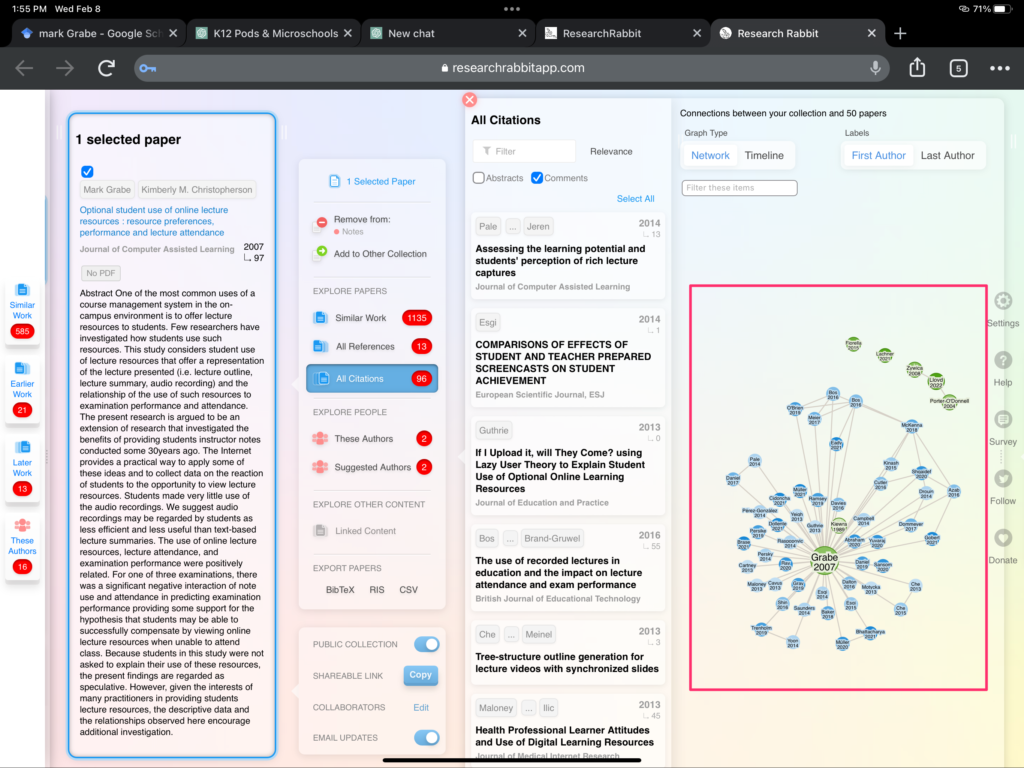
There are several other tools that offer similar capabilities, but these two tools typically provide me plenty of resources to consider
Stage 2
Now what. I can review the abstracts of papers that seem relevant to prioritize a bit, but I keep hoping that something more would be available to get me started.
I wondered what I could learn with ChatGPT and I have been experimenting. My exploratory strategy has involved asking ChatGBT for information about papers I have written. The idea is that I know the information in the paper and I am trying to determine if a given tool will provide this information. Would I be able to ask questions about other papers and generate answers that are valuable and that I could trust?
The following is an example of this exploration and it is the text generated by my interaction. My inputs are bolded. I can enter a title for the paper and GPT will generate a credible summary. I would not offer this summary as different from the abstract, but it turns out to be similar and ChatGPT obviously can find information about a specific study based only on the title. This alone is at least interesting.
Summarize the journal article Optional student use of online lecture resources: resource preferences, performance and lecture attendance
The article investigates the optional use of online lecture resources by students, including their preferences for different types of resources and the impact on performance and lecture attendance. The results suggest that students have diverse preferences for online resources and using these resources can have a positive effect on performance, but may not necessarily affect lecture attendance.
Provide additional details
The study aimed to understand students’ preferences for online lecture resources, such as videos, slides, and lecture notes, and how these preferences impact their academic performance and lecture attendance. The study found that students have different preferences for different types of online resources, with some students preferring videos while others prefer slides or lecture notes. The results also showed that the use of online resources can have a positive impact on students’ performance, but there was no significant effect on lecture attendance. This indicates that students may use online resources as a supplement to attending lectures, rather than as a replacement. The results of this study provide valuable insights for educators looking to incorporate online resources into their teaching.
What statistics were used to analyze the data from this study
The information on the statistics used in this study is not specified in the description given. To know more about the specific methods and statistics used in this study, it is best to refer to the original article.
How was class attendance determined
The information on how class attendance was determined in the study is not specified in the description given. To know more about the specific methods used to determine class attendance in this study, it is best to refer to the original article.
What were a couple of the preferences for online notes the study identified
The information on specific preferences for online notes identified in the study is not specified in the description given. To know more about the preferences for online notes identified in this study, it is best to refer to the original article.
I am guessing ChatGPT is limited exactly as it suggests. The full published study requires paid access either by a library or individuals and this AI tool’s knowledge base does not include this information.
Elicit
Elicit uses AI to provide deeper insights than I was able to generate with ChatGPT. I doubt this is the advantage of the AI engine it uses, but most likely the result of the knowledge base it can access and the presets to look for specific things. Beyond the presets, Elicit provides the opportunity to ask custom questions and I was able to get answers to some but not all of the questions I failed to find answers for using ChatGPT. Sometimes I had to rephrase a question several times to generate the answer I knew was there. What I really wanted but could not get was a summary of the Methods section. I don’t need the results because the results are just math and can be approximated from the Abstract. The key to answering many important questions is the Methods that are applied as with this information one should be able to find factors necessary to interpret the Results and possibly explain differences between studies.
I recommend others with goals similar to my own take a look at this AI tool. The following images offer a peak. Some of what I describe as presets are shown in the red box in the first image. The opportunity to ask specific questions about the study is shown in the second image.
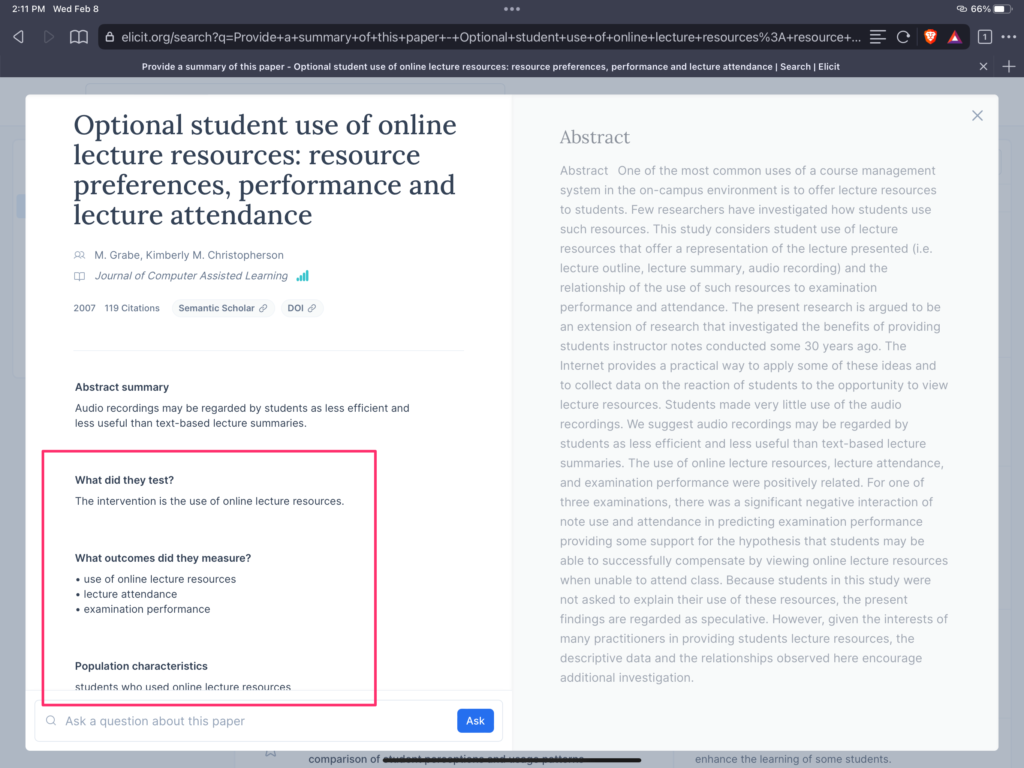
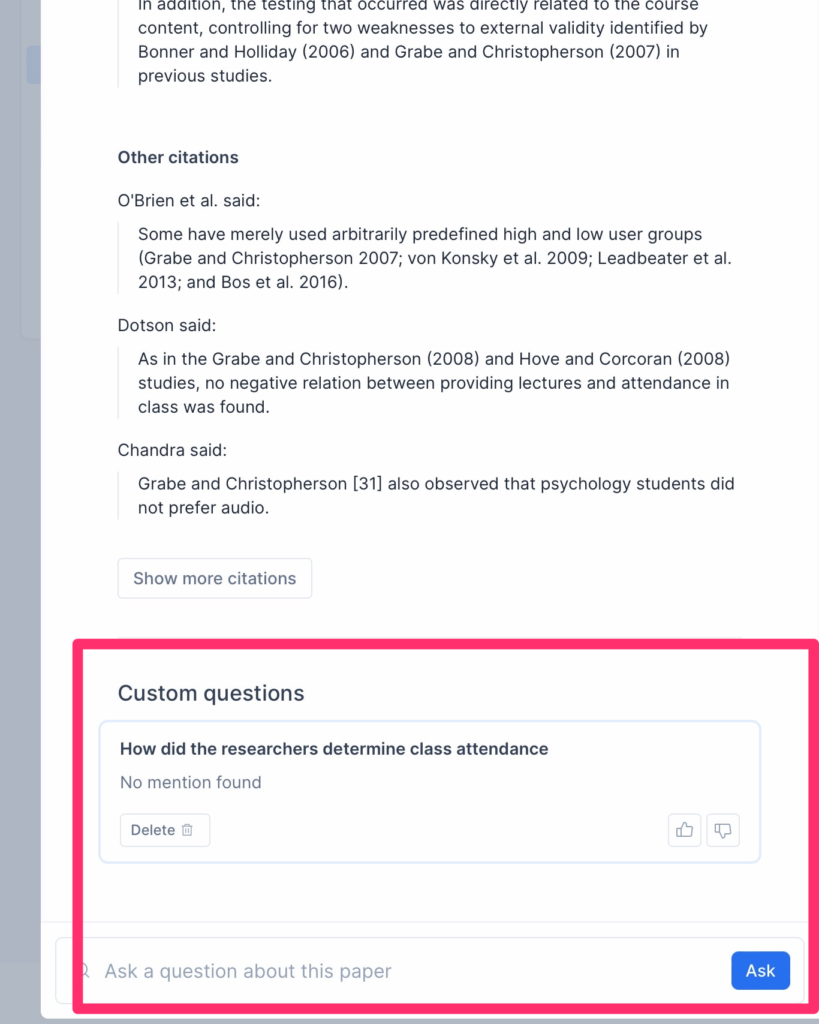
The summary and other information provided by Elicit was more detailed than the summary provided by ChatGPT.
Stage 3
Now it is time to make a few selections and invest the time required to read papers predicted to be most valuable. This ends up being a never-ending process with new questions emerging and reuse of the same tools over and over again.
My point. It is time to explore. I have made a start on exploring AI tools for my own niche interests and perhaps I have offered some ideas you might use. Beyond that, I think this is the stage we are at and it would be useful for more individuals to see what AI tools offer for their own personal needs and share what they discover.
![]()
You must be logged in to post a comment.