I have had this question about the power of search that I finally thought of a way to investigate. My question involves the power of search to locate content in sites that use a database backend. So, instead of independent web pages this would be systems that generate a web page on the fly by accessing a database to retrieve content as requested. Blogs work in this way. So do content management systems such as Concrete5.
I am guessing that the search spiders find the static front page of a blog or content management system, but would not necessarily trigger that source to pull up content from the database so that it could be indexed. My concern has been that resources I offer within a content management system are not going to be located when someone searches for something the stored content might address.
Here is how I tested my concern. I recently switched from content stored as individual web pages to the same content stored in Concrete5 (a content management service). I did this so I would not have to continue paying for Dreamweaver to add content to my existing site or to modify existing content. Blogs (e.g., this WordPress site) allow a user to save content as pages instead of posts. These pages can be linked and thus can provide the same functionality as a site constructed page by page using an authoring environment such as Dreamweaver. Blogs and content management systems now provide access to themes and other features that make content creation far easier than used to be the case. If your content is fairly standardized (most pages look the same) and require only the presentation of content (text, video, images), why invest in an approach that allows far more flexibility but at the cost of efficiency and funds? There may be an answer to my question – searchability.
Anyway, my server presently contains redundant versions of book resources one in the form of independent web pages and the other in a database enabled content management system. What I realized was that I could do was conduct a search on a paragraph from this content (both sources) and see what was returned. Google advanced search allows you to search for an exact phrase (see second image) which I copies from a page within the database-based system. The same paragraph appeared on the original page-based site created with Dreamweaver. Instructors may have used this same technique when concerned that students have copied content from the web to include as part of their own writing.

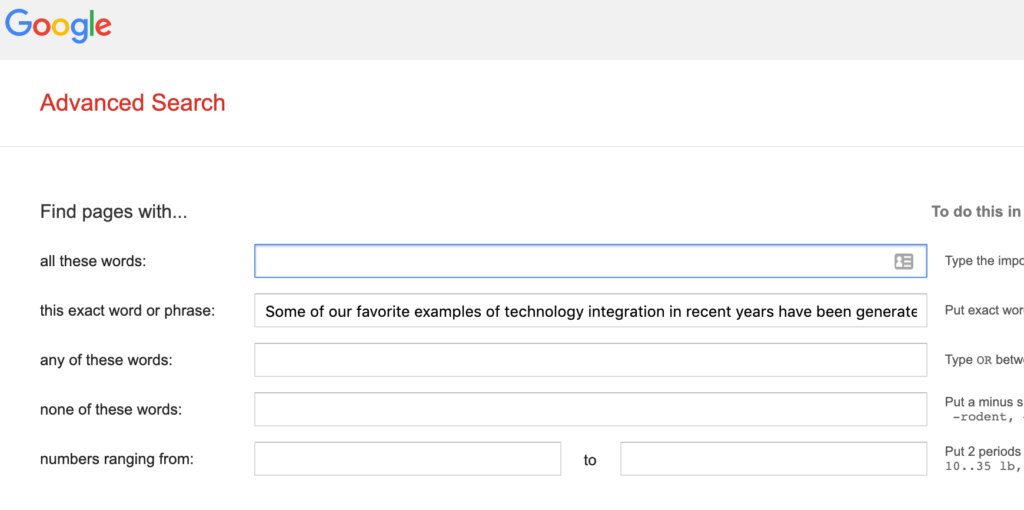
The results of the search confirmed my concern. The search located the page with the target paragraph, but not the same content from the active content management system.
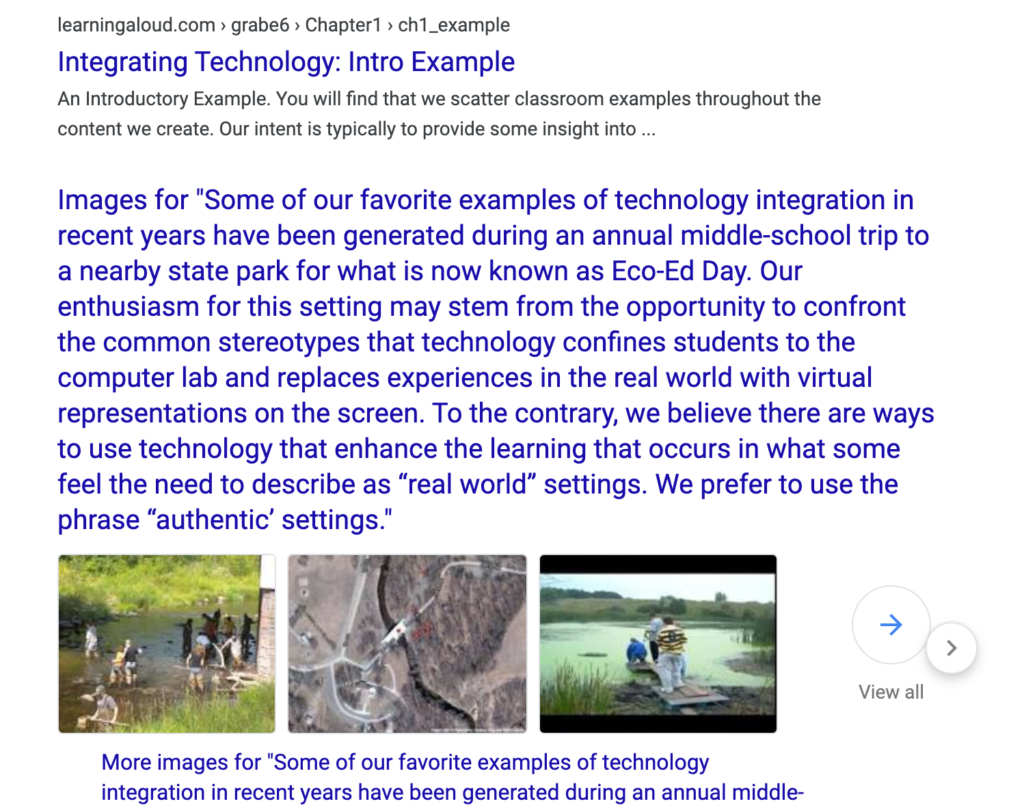
I am now trying to figure out how to promote my content when it can no longer be located through search.
![]()
You must be logged in to post a comment.