When I was doing the research for my previous post and doing some searches on my own content I came across this site.
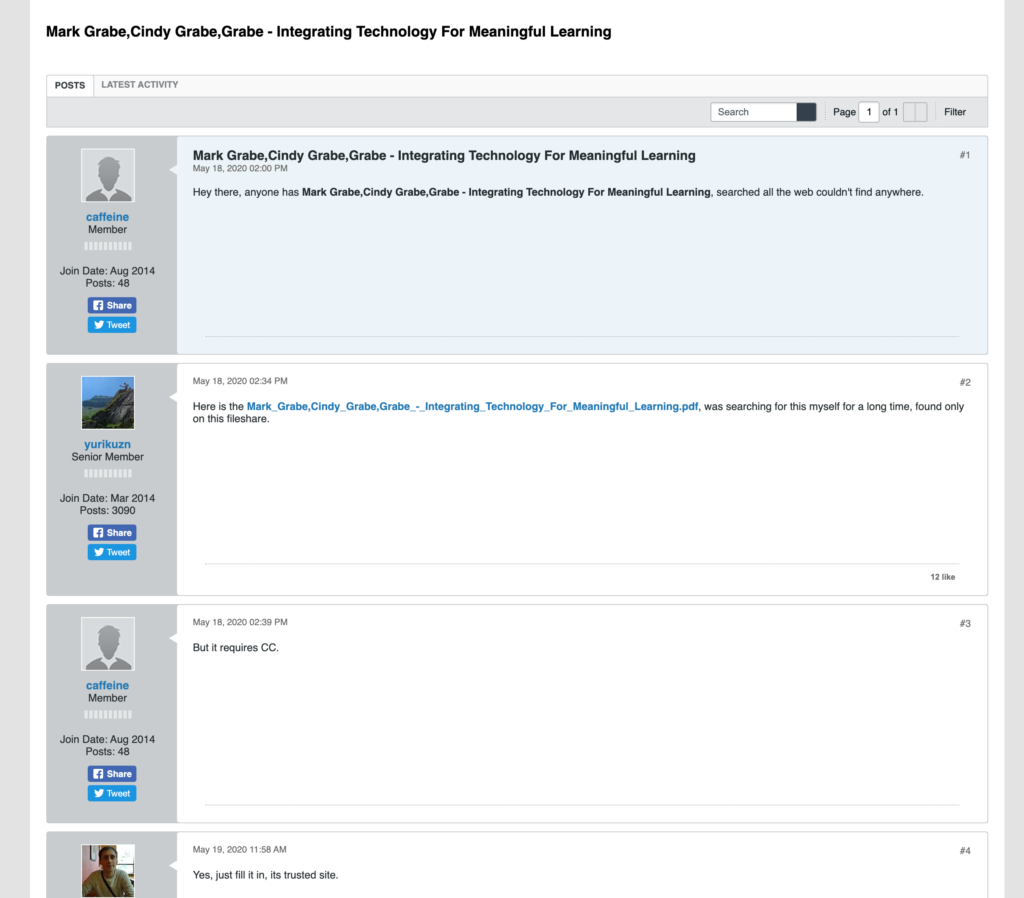
What this site provides is a way to download at no cost, our textbook. You can get it as a pdf, mobi file, and a couple of other options. Going through the letters of appreciation (not to me) and the notes about it being provided under a CC option (creative commons), I could not help but become a little frustrated and a bit angry.
This content was stolen. Our book is sold through Amazon for $9. We sold previous versions of this book through first Houghton-Mifflin and then Cengage for well over $100. We opted out of that arrangement which was quite lucrative because we were unable to convince Cengage to go to a $29 model consisting of a paper Primer and a free web site. Through an arrangement that returned our copyright, we moved our Primer to Amazon ($9) and offer our supplemental resources at no cost on our own server. If you are interested in the logic for our model, search this site for book (I will tag this post so you can read our explanation). In short, there are advantages to our model that include lower cost, less dated content, and greater flexibility in what instructors can assign. This was not a decision we made intending to make more income and without the promotion of a major publishing company we receive a fraction of the income generated by our original paper textbooks.
I find it hard to believe that college students cannot afford to purchase this textbook for $9. Whatever anyone thinks of the cost of textbooks and what complaints one might have about this industry, these issues do not apply to us. Because this is a textbook intended for practicing teachers involved in graduate education and preservice teachers, I find it disturbing that people in this line of work would be so unethical as to steal a $9 book.
Maybe I am being too hard on the students who did this, but I assume they know or don’t want to know. This is a current book and not a book developed through a source of external support to warrant the phony creative commons representation that someone other than me has claimed for this work.
OK – end of rant. Just be honest and respect the effort and skill required to generate the content you use.
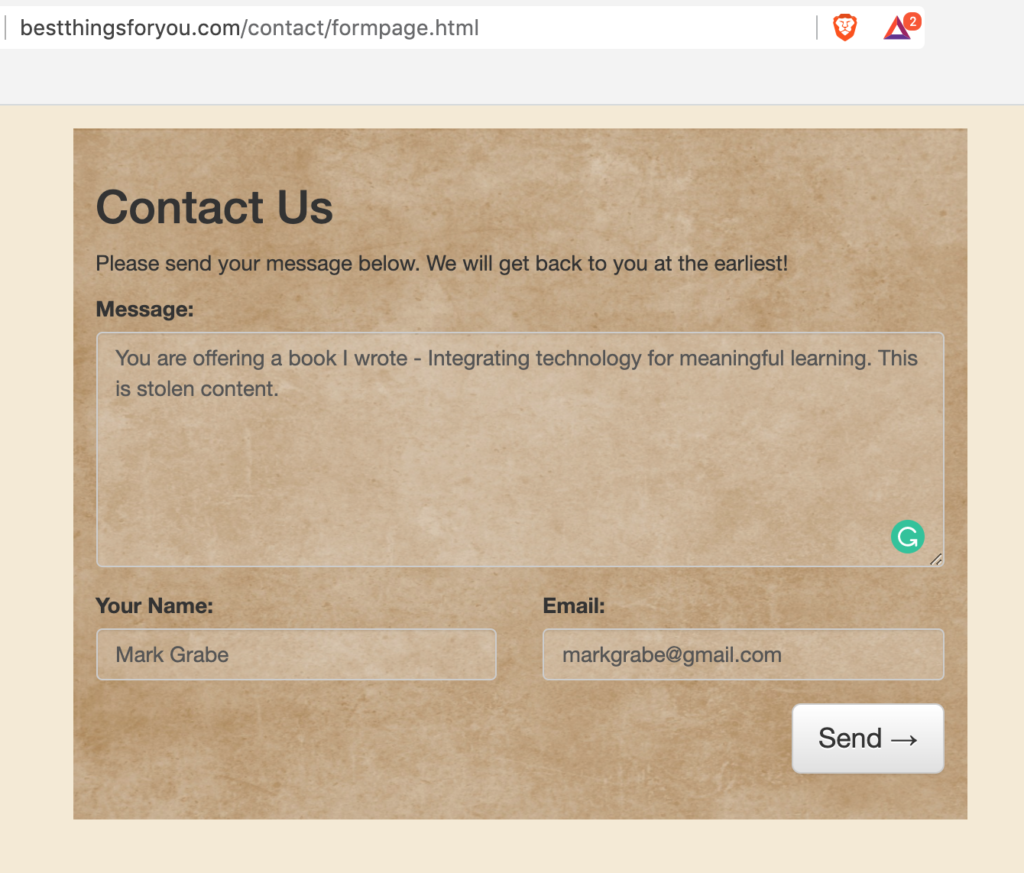
P.S. – The day I wrote this post I also responded to the site using a form that was provided. I kind of knew that if the site wanted responses in this fashion instead of via email I was unlikely to receive a response. I have not and the pirated book is still available.
![]()

You must be logged in to post a comment.