Tagboard allows users to follow content across multiple services (e.g., Twitter, Google+).
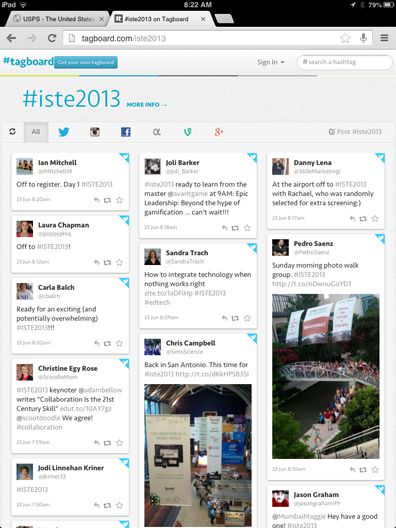
It occurred to me this might be a perfect time to try it out. ISTE (International Society for Technology in Education) is underway in San Antonio. This is a very large conference focused on the use of ed tech in K-12. We always attend, but this year decided to stay home and save our energy for an upcoming trip to Russia. Anyway, with 15-18 thousand attendees generating all kinds of content based on their experiences (good and bad), you can pick up a lot by just following the stream of content.
The tag for the conference is #iste2013. You can search for this tag within a given environment (e.g., Twitter), but why not search across services. This is what Tagboard allows. This is a web-based service. Use the link above to give it a try and see what you think. This would be a good time to experiment.
Microsoft recently announced their tablet would be donated to 10,000 educators attending this year’s ISTE conference and the device would now be sold for $200 in the education market. You wonder whether this is a way to get rid of inventory that will not sell, a clever long-term marketing strategy, or both. Anyway, these announcements got me thinking about why it would matter which device I use and which I would recommend. Have we reached the point that price should be the deciding variable?
This question has frequently been framed as whether tech hardware (e.g., laptop, tablet) has become a commodity. My interpretation of this term, given my ag background, is that the value of different products is roughly equivalent (e.g., corn, milk) so the expectation is the cost to purchase should be very similar and because of competition low. A Mac Pro would not fall into this classification. The question, if you are an Apple advocate, is whether the term should be applied to the iPad and say the Air.
I assume the coming days will see comparisons of the iPad, Nexus, and Surface. I do not own a Surface, but I have both iPads and a Nexus. My consumption and production needs can be accomplished with either. I still find the iPad a little easier to use and there are apps I prefer on this device. I admit in nearly all cases there are alternatives or I assume developers will eventually get around to making unique apps cross platform should the number of competing products reach a critical level.
What I happen to value now is that a device get me to the things I want to do in the cloud. Frequently, I need to work with Google apps, but this access could also involve Feedly, Evernote, DropBox, Box, Flickr, Diigo and probably a few others that do not come immediately to mind. Both Apple and Microsoft seem to be attempting to ramp up their cloud presence – the cross-platform opportunity to use iWork apps and Microsoft Office 365 seem promising (as long as the work better than Mobile Me). I bothers me a bit I do not see the revenue stream in all cases, but I leave that to the companies to work out.
For those of us who work to support classroom use of technology, a commodity mentality would discourage such a great focus on the identification of the next new thing and a greater focus on creative and productive ideas for using a core set of tools. Consider the popular conference sessions during which several well-known presenters attempt to wow the audience by demonstrating services and devices few know about. Entertaining, but not that productive. Interesting activities for classroom use would end up being far more helpful.
That all sounds like we are moving into an era of DULL. What could be wrong with commodity devices? The concern I think is the lack of motivation to improve capabilities rather than reduce cost? You might imagine this as the Dell vs. Apple approach. Where will the profit margins necessary for innovation come from?
Data protection is obviously a very important issue and companies that encourage us to use their services to store our data must take security seriously. Two-factor authentication has been developed to offer greater security. I have heard two factor authentication described as something you own and something you know. Cute and easy to remember, but the operationalization translates as “you know your password” and you “own your phone”. In concept it works like this, once you turn two-factor authentication on, your existing services are immediately disabled. You now must use the two factors to activate them again. So, instead of using your password which is initially rejected, you use a code (a number) that is sent to the SMS system on your phone when your password fails.
Here is my problem with this system. It seems designed by engineers with little insight into how real people actually use devices. It first assumes you have a smart phone (there is a way around this, but the way around makes the process even more complicated). Second, it is not system wide approach and must be completed for each device. My situation involved authenticating (so far) on my phone, two iPads and a Nexus 7, three lap tops and three desktops. This may be a little extreme, but not really. I have equipment purchased for me by my university and equipment I have purchased for my personal use, etc.
It gets worse. I commonly use Google apps through a browser. For a time, I had to authenticate each time I opened the browser. This was a hassle because I am not one of those tech guys who carries my phone or enjoys doing all possible things with it. The issue here concerned my phone settings. As a security measure (I use so many different devices – mine and public), I had my browser set to delete cookies when I shut down. Hence, the engineer’s solution of permanence was to set a cookie. So, I changed this permission and this seemed to fix the problem with browsers. It is kind of funny though, don’t you think, to address a security issue by eliminating a security precaution?
OK, so you authenticate once using something you have and you use your password (something you know) each time and you have a cookie set and this fixes the browsers (once for each one by the way). Then there are your apps. Apps don’t set cookies (I don’t think) so this process will not work for apps. Google has apps. What were they thinking?
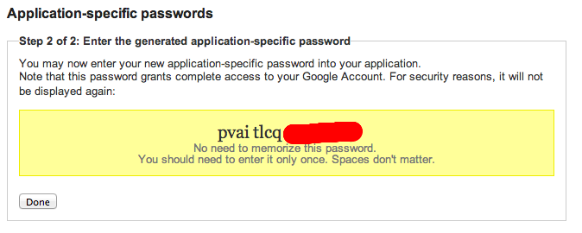
There is a completely different system for apps. Instead of the app sending a message to your phone and setting a cookie, you request an app-specific password using your device and you are sent a 16 element password to enter. You destroy any evidence of this display. Then, the app works. Again, repeat with all devices.
OK – perhaps there is a better way and I don’t understand. However, what I have described here works, but was labor intensive.
I am concerned. I am heading to Russia for three weeks. I value security, but I also do not intend to take my phone. I know there is a way to request multiple codes I can take with me (printed on a piece of paper in my bill fold). I keep thinking there must be a better way.
I find the data generated by my web site to be very interesting. Big time web players study such data carefully in order to optimize their web business. I study such data because I am curious.
I have noticed a specific down turn in traffic lately. One factor that seems to have changed is the number of hits that result from search. So, analytics can determine the referrer for a hit and I can identify hits resulting from searches.
So why might search hits diminish (aside from the obvious possibility that I write about stuff others find less interesting). Here is something I wonder about. Can Google tell the difference between a link farm and a social bookmarking service?
One prominent variable in the Google ranking strategy involves the number of sites linking to a particular site. A simplistic way some have tried to “game” this system is to set up multiple web pages with links to other sites the scammers would like to see ranked higher in Google searches. The Google ranking model attempts to identify such artificial way of creating more links (link farms) and to discount such sources.
There are legitimate sites that consist largely of links to other sites. For example, a social bookmarking service or even a simple effort to archive useful sites as a service to others would consist of content with high link density.
One of the services on my site was developed as an open source bookmarking site. I became interested in a service called Scuttle because it allowed me to operate my own bookmarking site. It was written in php/MySQL and I spent time adding some features. I created a ranking systems based on the number of times users actually visited one of the sites listed. I also created a way for users to evaluate the sites (one time only) when conducting a search and this also contributed to the ranking.
I have had some difficulties with this site. I ended up disabling the evaluation feature and the login feature because both involved users logging in and logging in allowed users to add links I might find objectionable. There was one upgrade to Scuttle. I did not make the transition because of the changes I made to the original and the lack of enthusiasm for starting over again.
I am not trying to decide whether I should delete this service. It does generate some activity, but it also causes problems. As a hobbyist I enjoy creating resources for others to use, but I do not want my other content to go unused because the content would infrequently surface in searches. There must be a way to figure this out.
Earlier this Spring we learned that Google planned to abandon Reader (the RSS reader) and many of us wanting to be proactive began looking for alternatives. While some believe social (Twitter, Google+) has replaced the practice of following multiple information sources (mostly blogs) searching for enlightenment, I still invest time in specific individuals I think provide useful content and believe the accumulation of comments from these individuals offers something of value beyond isolated new ideas that may be surfaced through recommendations.
Anyway, my present choice for reader/aggregator is Feedly. I abandoned Reeder (different from Reader) because originally it appeared that Reeder was just a way to explore Reader feeds. I know this may seem confusing to those who do not use RSS. Now, the Feedly blog suggests you may not have to move to Feedly from Reeder. I realize this is counterintuitive, but this is because I explain a possibility raised in the Feedly post Feedly may not have intended. Feedly intends to play the roll Reader played in serving as a source for other readers (usually because the other readers were more attractive or offered some other useful feature) and to develop the capability before Reader goes away.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
You must be logged in to post a comment.