
I created the phrase “layering for learning” some years ago to describe a collection of digital tools with a specific educational purpose. The phrase refers to online services that allow educators or learners to add instructional elements to existing web pages or videos without modifying the original content. Educators might want to do this as an alternative to textbook content to offer more current information or to have learners deal with the type of information that they encounter outside of the classroom environment.
A layering tool works by retrieving content from a creator’s server and combining it with a second “layer” of additions from the layering service’s server in real-time. The combination is what the learner experiences. This approach transforms raw, passive information resources into active learning experiences while respecting the original creator’s copyright and revenue opportunities, as hits and ads are still recorded on the source server. This may sound unusual, but the mental image of a layer of additions on top of the base of existing content is one way to understand how this works. The simplest example is probably highlighting. Instead of making a permanent change to someone else’s content by marking up their work, the layered appearance of a highlighted web page is available only when the learner’s experience combines content from the content creator’s server with the layer from the server providing access to the layering tools. Different approaches exist; I focus mainly on those that individualize the experienced product to include the additions of a teacher and of an individual student.
Layering for Generative Experiences
The fundamental purpose of layering is to implement generative activities, which are external tasks intended to encourage productive internal cognitive behaviors. While learning ultimately occurs in the student’s mind, educators can use layering to indirectly manipulate and increase the likelihood of specific mental actions. Questions make a good example of a familiar generative task. A question is added to a learning situation to encourage different types of thinking (cognitive activities) on the part of the learner.
From your personal experience, give me an example of xx.
How would you define xxx?
Layering tools allow these tasks to be embedded directly within the flow of content, rather than being isolated as separate assignments. Textbooks typically offer questions at the end of chapters, or sometimes at the beginning to direct attention. Researchers at one point explored questions embedded within text – adjunct questions. The idea was to immediately check on understanding while the student could easily reference the relevant content. There was some value in this approach, but my guess is that extending the length and hence cost of textbooks was rejected.
There are several categories of generative tasks that can be implemented through layering:
Knowledge Activation: Before or during exposure to new material, layering can be used to insert prompts that ask students what they already know about a topic. This “pre-questioning” effect helps activate relevant existing knowledge, which serves as a base for interpreting and anchoring new information.
Elaboration and Personalization: Educators can layer prompts that require students to go beyond the provided information by generating personal examples or connecting concepts to their own life experiences. This encourages knowledge building – where the learner adds to core ideas from personal knowledge – rather than mere knowledge telling, which involves a simple restatement of what was read or heard.
Summarization and Paraphrasing: Layering allows for the insertion of tasks where students must pause and rephrase the most important information in their own words. This process requires the student to select essential information and organize it into a coherent structure, which is a significantly more powerful cognitive act than verbatim transcription or passive highlighting. Of course highlighting also has some unique value in preparing for review.
Comprehension Monitoring: Layered elements can serve as checks for understanding by forcing learners to evaluate their own “calibration” – the accuracy of their self-perceived mastery. Proposing questions that students may not be able to answer encourages them to reflect on gaps in their understanding and take remedial action, such as re-watching or re-reading a specific segment.
Retrieval Practice: Embedding multiple-choice or short-answer questions directly into a video or article facilitates the “testing effect”. Actively searching memory to answer a question strengthens future retrievability and understanding more effectively than simply studying external notes. This use works most effectively when repeated after delays from the original encounter or earlier study activity.
Interactive and Social Processing: Some layering services allow for social annotation, where thinking is made visible to a community. Students can share interpretations, respond to peer comments, or engage in threaded discussions directly on the digital document. This interactive layer provides a second input beyond the original source, prompting learners to reconsider and potentially modify their understanding in light of others’ insights. This experience might be exemplified through opportunities to discuss or debate a point.
Some of these activities are intended to impact learner as part of the initial exposure to instructional content and some during later review activities. In practice, layering tools are specialized for use with video content or as an addition to what are commonly called web pages. Adding generative elements to PDFs or text files is also possible, but this post deals specifically with repeatable use of online experiences most likely while using a browser.
Insert Learning – A Layering Environment for Web Pages
Insert Learning is a service for layering web pages I like to describe as this service offers the complete package of instructional content design, personalized lesson assignment, and the evaluation of student effort and if desired feedback and grading.
My experience with this tool involved its use in several instructional design courses in which the service was used with these students expecting the students would understand how the same tasks could be applied in situations in which they might apply similar activities in their own work.
This is a subscription service although you can explore without subscribing. The cost is $100 per year or $20 per month with unlimited students for this price. I used to pay by the month because the course in which I used it was a semester long.
Think of this service as two parts. There is the administrative and learning management component, accessed via a website, and the lessons, accessed via a web browser extension. When a student opens a lesson or the instructor works to add layered components to a web page, a menu bar will appear on the side of the browser window (see below). This menu bar provides access to the available tools. A student will have a shorter list with highlights and annotation options. The instructor can highlight, annotate (actually add various text elements including links), insert questions, and add a discussion window that retains the comments added from other students.

The following image provides a better idea of what a layered page looks like when additions (an essay question) and a text box containing a link look like.
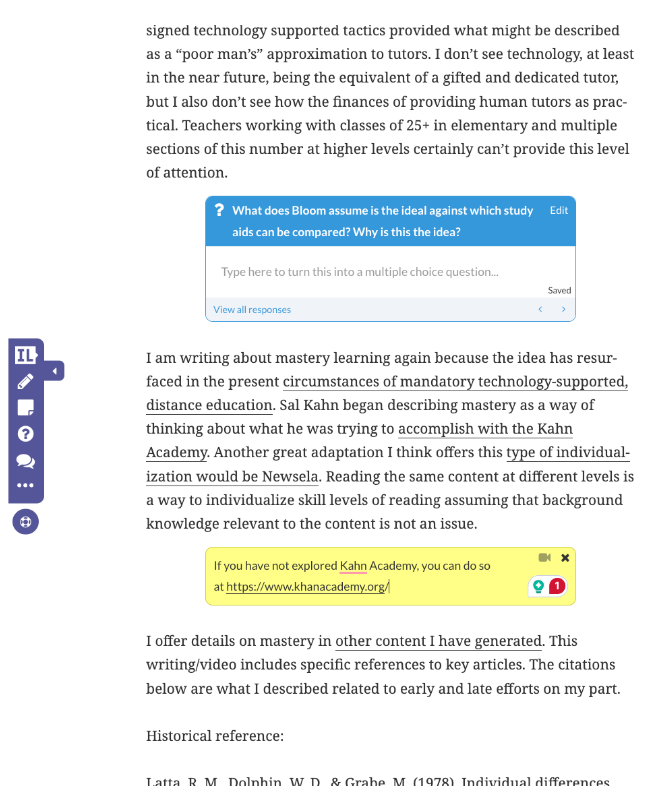
Insert Learning collects student responses and allows then allows the instructor to respond with feedback, award a score if desired, or simply check to see if students have completed a task. The following screen capture is what this would look like when reviewing what students in one of my classes had generated in response to a specific questions. You can see at the top of the image how I would determine which class, lesson, and item, I wanted to review.
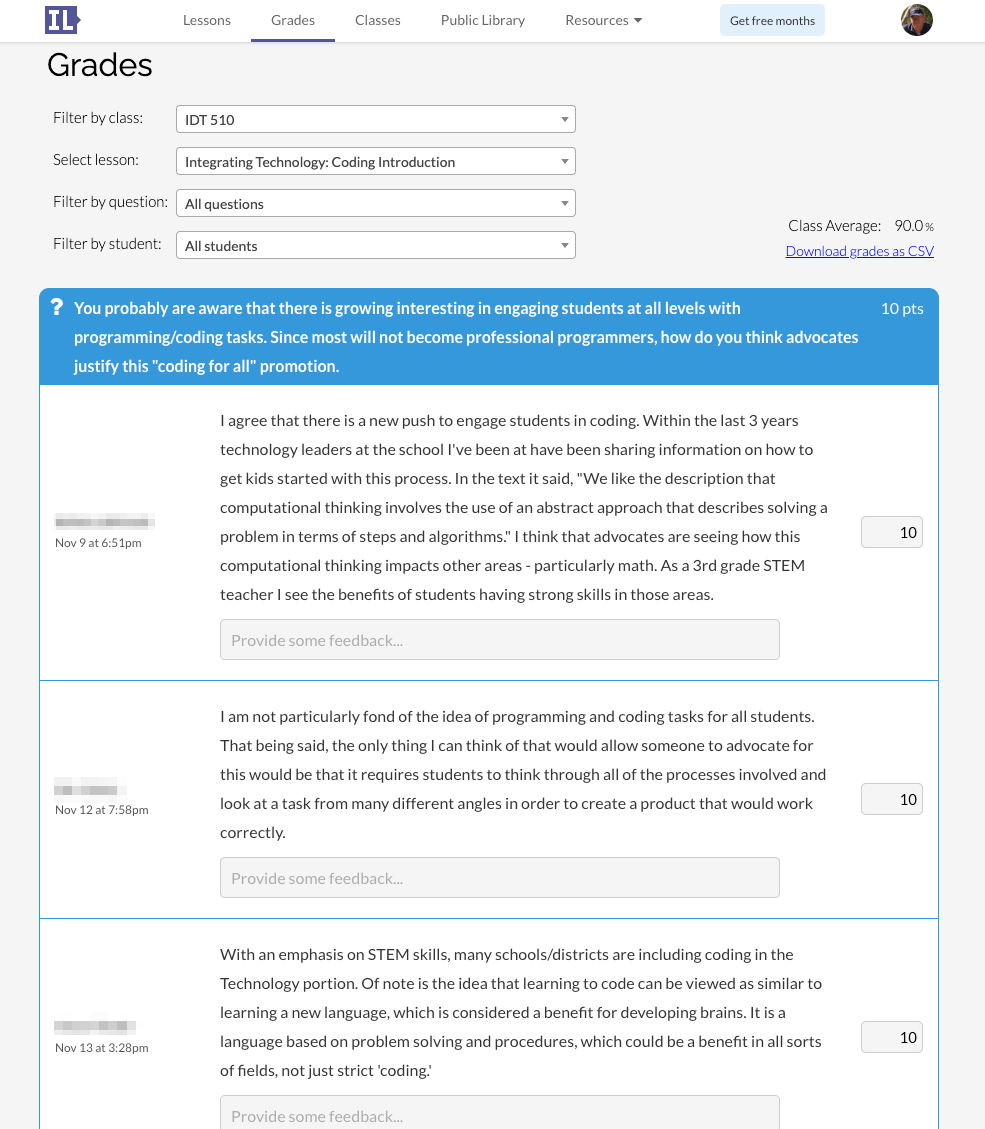
The following image shows the way I would assign individual lessons that I have accumulated.
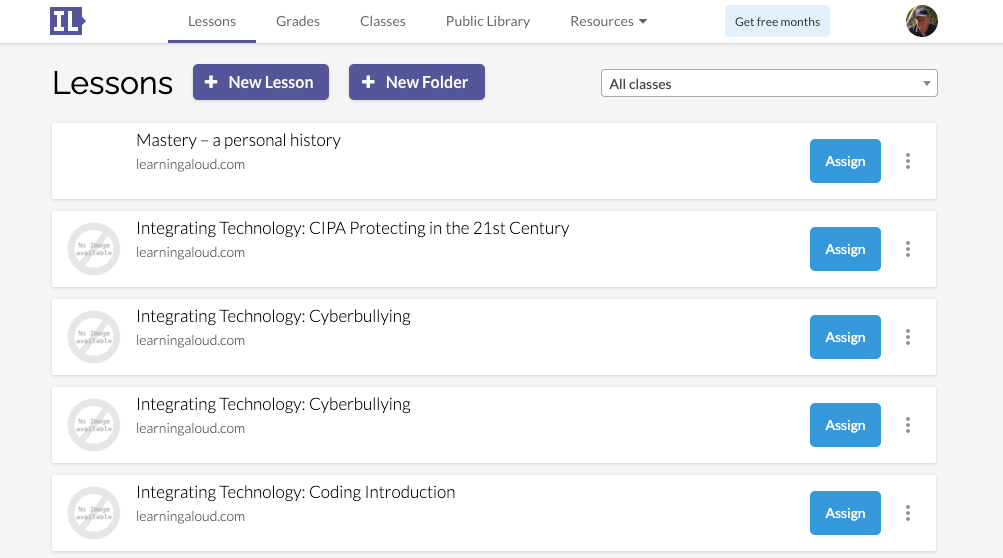
As I said, Insert Learning is a complete environment consisting of what I would describe as a learning management system, a method for lesson creation/design and presentation, and tools for feedback and evaluation.
I created this post mostly to explain what I mean as layering for learning tools with brief exposure to one example. I have additional descriptions of other tools both for video and for web pages that offer similar, but sometimes less complete capabilities. For web pages, the most similar product I have explored is Scrible (see below). The tool bar (top) and highlighting and annotation capabilities are visible. The question and discussion capabilities are not available, but the LMS approach is similar.

Final Comment
I think of summer as a time K12 educators and tech people might explore tools and perhaps develop some content for the coming year. Perhaps this post will offer them some ideas they might try.
![]()


You must be logged in to post a comment.