
The number of my recent posts focused on AI applications has probably started to blur together for many who follow this blog. I admit that at a basic level, the services described are similar. However, the services I describe have been optimized for different purposes and for individuals with specific needs. This service, Scispace, is focused on those of us who read academic research papers. The basic idea is to be able to generate from such articles quick summaries and insights that may be helpful in generating and storing a quick overview and help readers when components of such articles involve unfamiliar elements (e.g., statistical procedures).
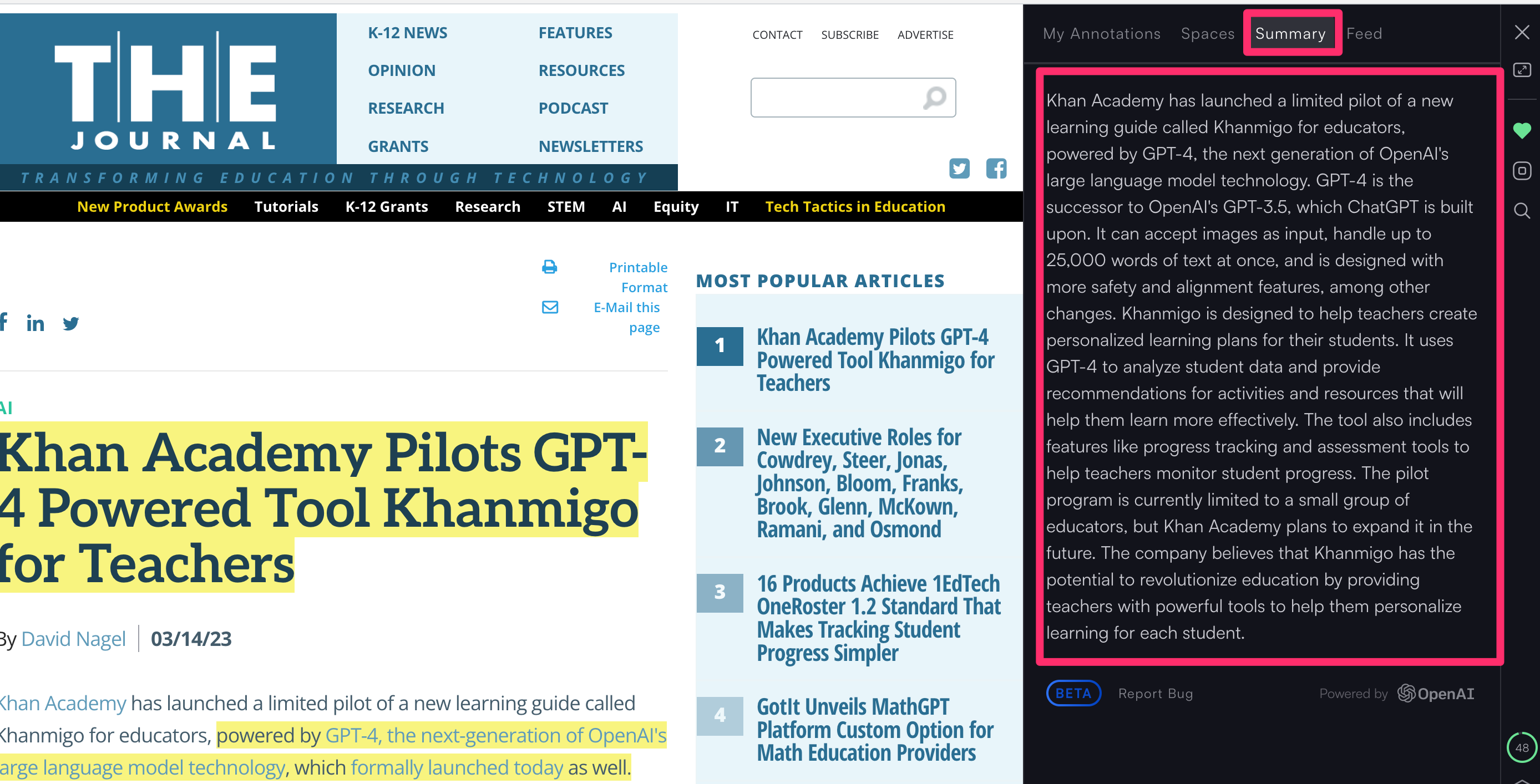
You either upload the pdf of an article you want to read or explore a pdf already added. The service is designed for users to create a library of articles they want to consult over time so this is not just for a one-time reading of articles. The basic design of the application is shown below. The article being read appears on the left and the AI inquiry panel appears on the right. I have added two red boxes to this panel to highlight two important capabilities. The box at the top opens a Discover dropdown menu which I will describe at a later point. The box at the bottom of the panel allows the entry of AI queries or the selection of a query from useful preselects.
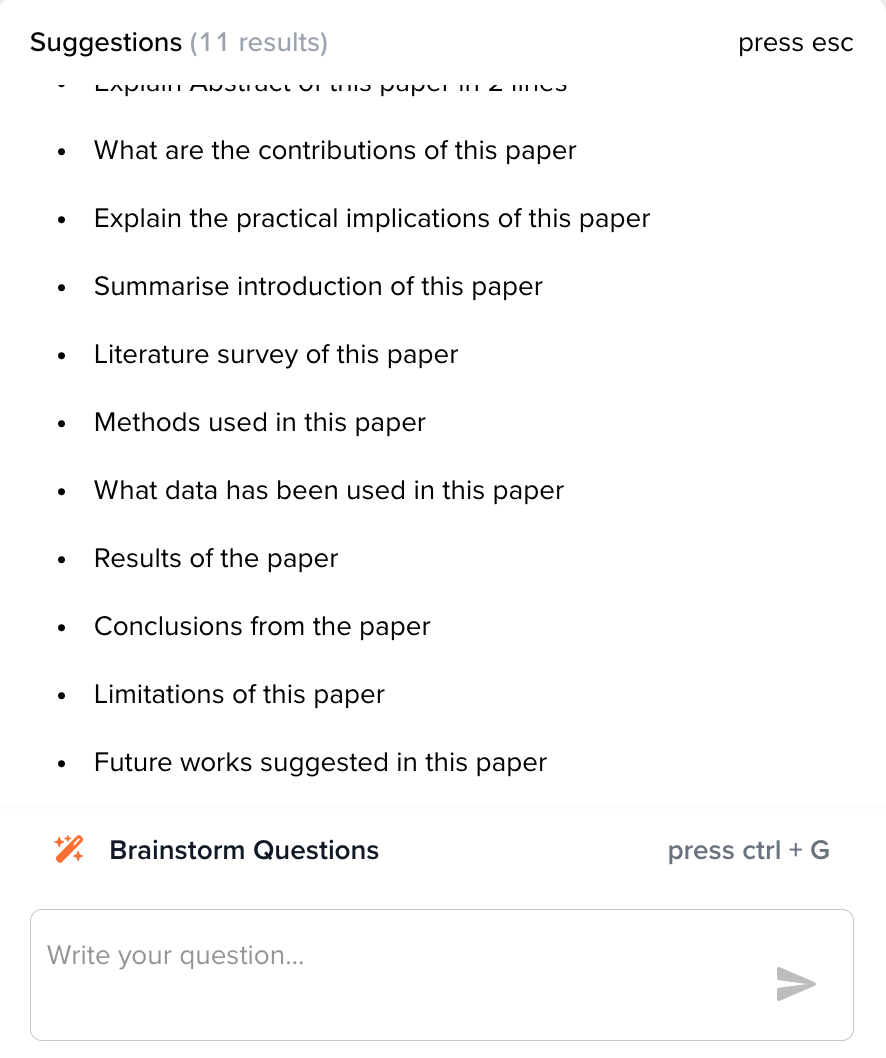
Some of the query presets are listed in the following image. These questions or questions you generate yourself can be applied to the article using AI.
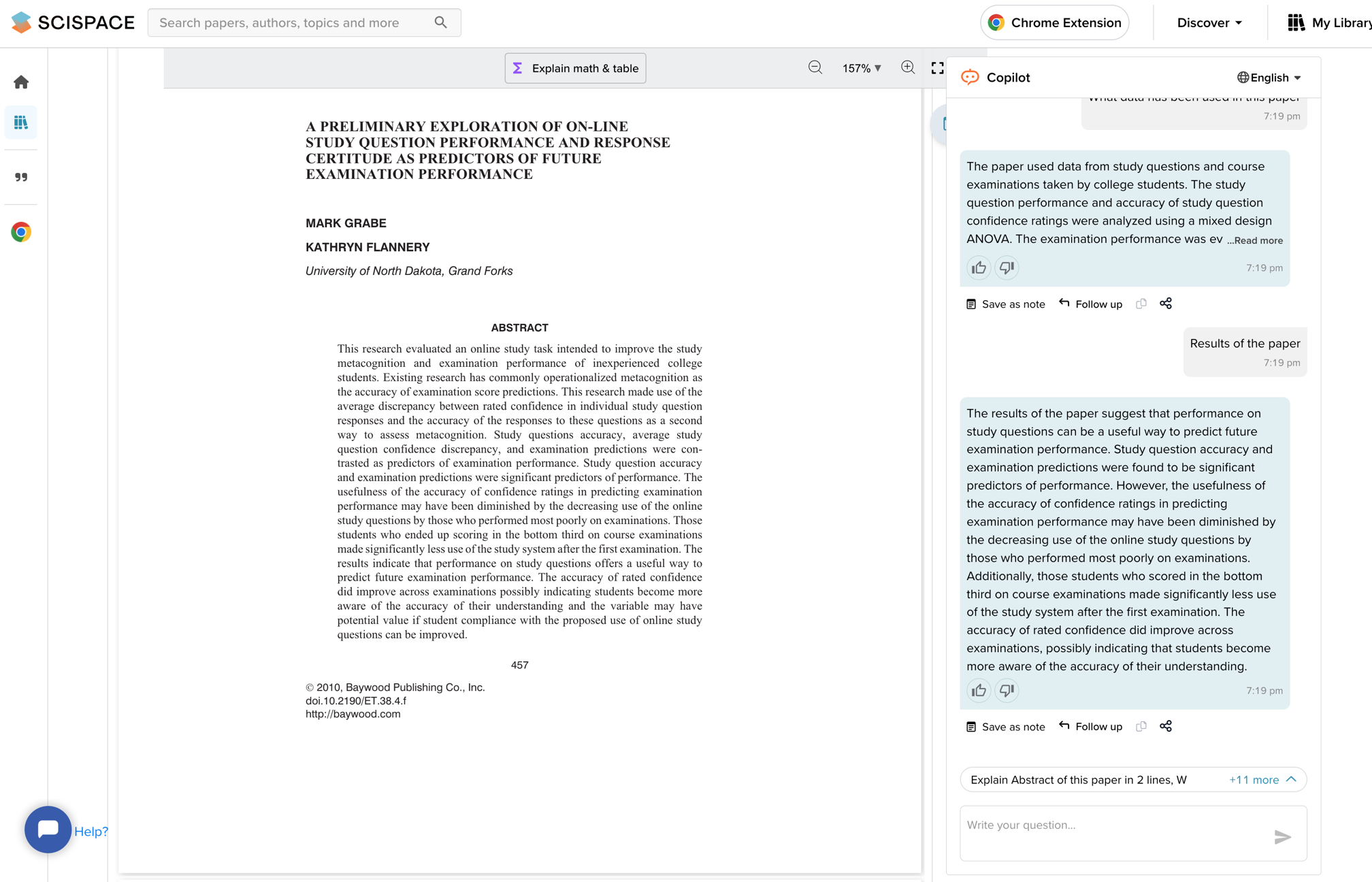
Answers to some of these questions for the article I uploaded are shown here,
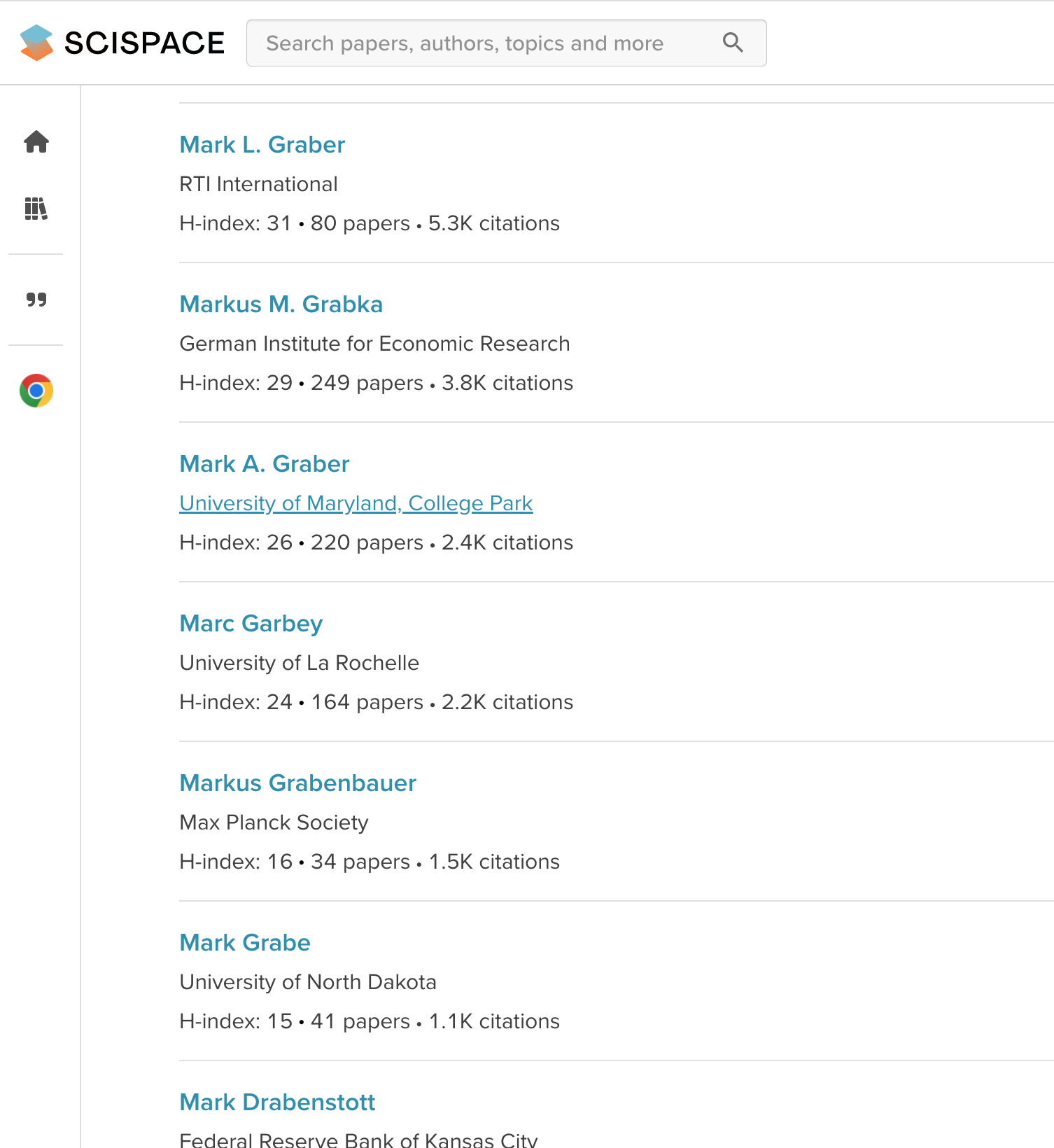
The Discover feature allows you to identify authors whose work interests you and then identify publications of an author you select. Yes, I did use myself in this example.
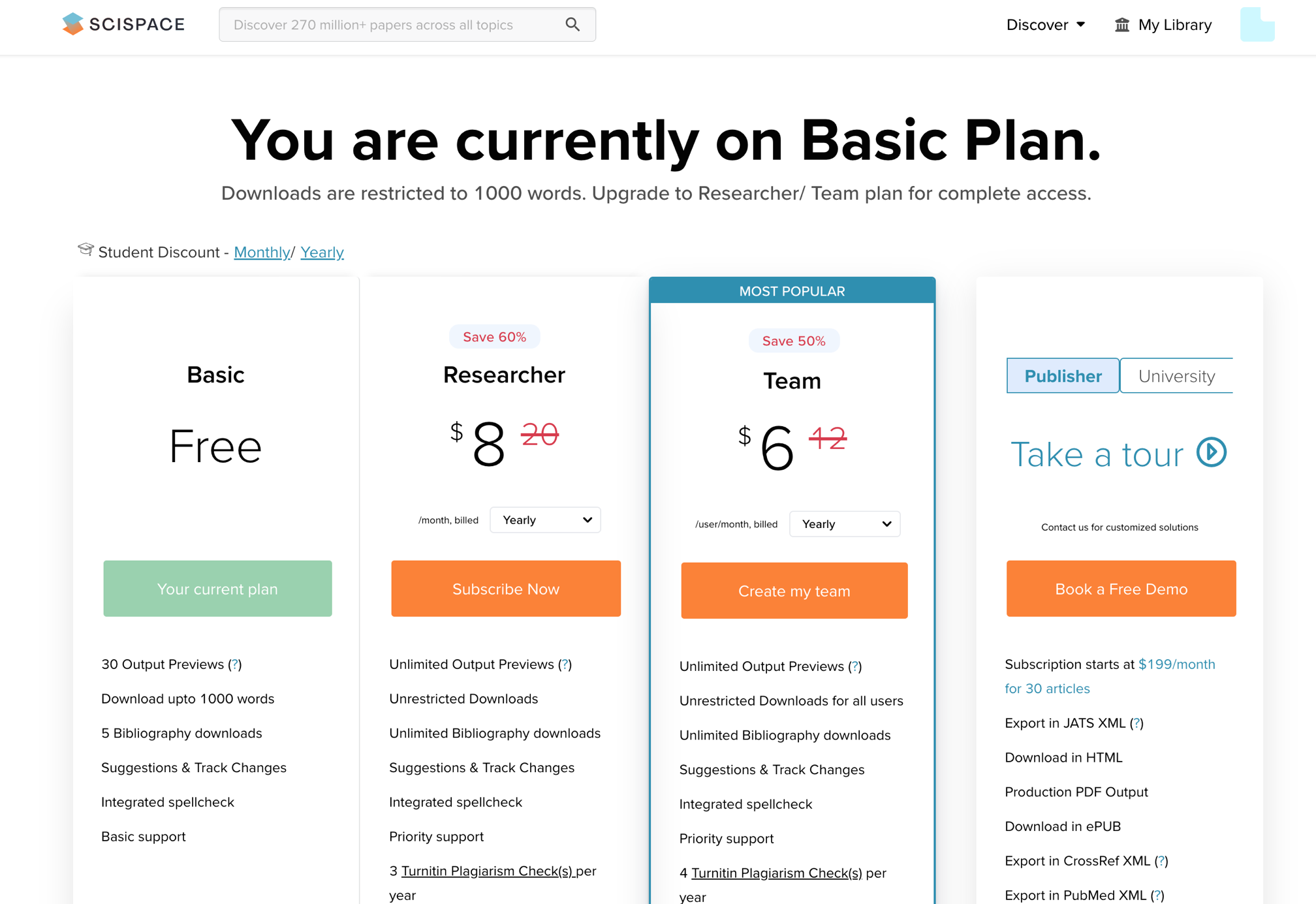
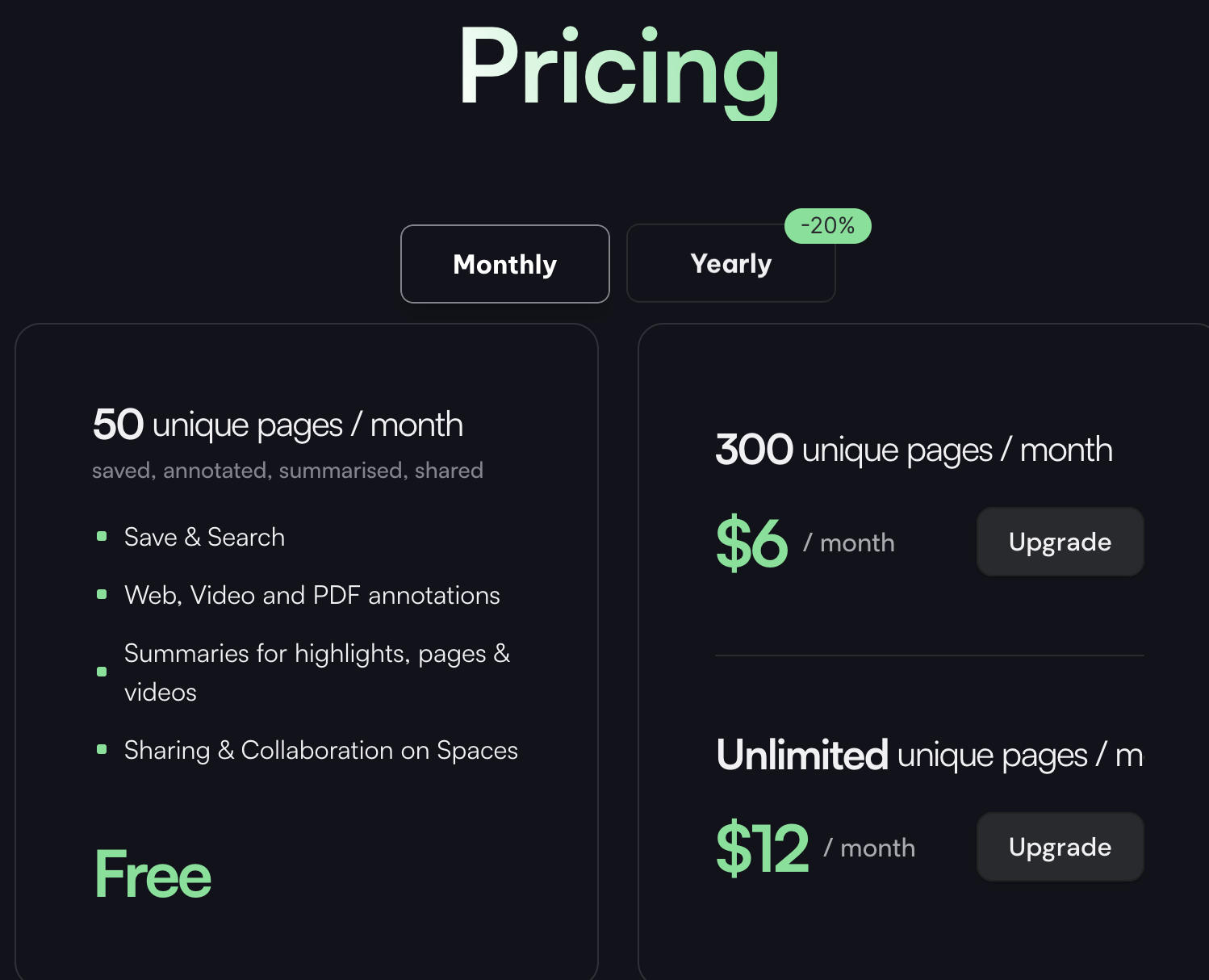
Unlike some of the other AI services I have explored, SciSpace does charge a fee for serious use. This makes sense as aside from just answering questions about pdfs you upload, it stores and allows the organization of these resources. Thus, there are infrastructure expenses associated with the service.
I see less personal value in the general question-answering potential of AI tools I have explored at this point, but I see how I can use AI tools targeting specific content I can designate.



You must be logged in to post a comment.